OCT Gateway DATEVconnect
Diese Anleitung beschreibt die Einrichtung des Gateways für DATEVconnect - dieses überträgt DATEV Daten in die staging Schicht einer OCT Datenbank.
Klassifikation
Merkmal | Wert |
|---|---|
Quelldatentyp | API |
Öffenliche Datenquellen API Dokumentation | https://developer.datev.de/de/product-detail/accounting/1.7.4/overview |
Steuerungsstruktur | Steuerungstabelle, welche die Aktivierung pro Mandant / Wirtschaftsjahr und Datenbestand ermöglicht. SmartSync Unterstützung: Mandant / Wirtschaftsjahr Dynamische Zeitauswahl: ja (im Standard aktuelles Jahr und Vorjahr) |
Validierungsoberfläche | Ja, Tabellenstatistik und Werte |
Zuletzt getestet mit OCT Version | 5.11 (für Cloudbetrieb, da erst ab dann Storage Account / Containersupport) 5.10 (on-premises eingeschränkt möglich, Tabs der Validierungsoberfläche nicht einspielbar) |
Programmierpattern | Table by Table (jede Tabelle ist individuell im Abruf definiert) |
Tabellengruppe | staging.DATEVCONNECT_* |
Öffentlicher Testdatenbestand | (geplant, auf Basis DATEV Mustermandanten) |
Konnektor für REWE Fachmodell | |
Konnektor für FIN Modul | vorhanden (Download über OCTBox) Doku |
Deploymentweg | Manuell, gemäß Anleitung auf dieser Seite |
Saxess interne Ressourcen |
Funktionalität
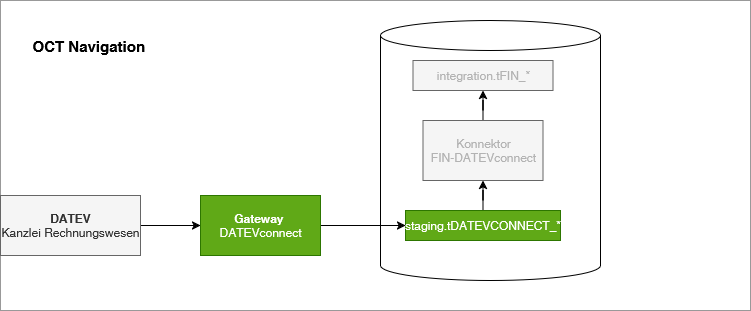
Das Gateway überträgt die Daten folgender DATEV Datenbestände in die staging Schicht einer OCT Datenbank
der über API DATEVconnect.Accounting https://developer.datev.de/de/product-detail/accounting/1.7.4/overview abrufbaren Daten
Mit diesen Datenbeständen lassen sich folgende Auswertungen erstellen
Bilanz und GuV mit der Auflösung bis auf Einzelbuchungen
Kostenrechnungsauswertungen, die NUR auf den KOST1 und KOST2 Buchungsfeldern basieren (Bezeichnungen für KOST1 / KOST2 Felder sind verfügbar, falls diese im ersten KOST System existieren)
Offene Posten debitorisch / kreditorisch
Dokumentaufrufe über Beleglink
Die OCT Datenbank stellt eine Validierungsoberfläche für diese Daten bereit
Systemvoraussetzungen
Systemvoraussetzungen DATEV
Zugang zu einer DATEVconnect URL mit einem Benutzerkonto, welches über lesende Rechte auf allen Endpunkten verfügt. Die Einrichtung von DATEVconnect unterscheidet sich, je nachdem ob:
der Kunde DATEV on-premises nutzt
der Kunde DATEVasp, DATEV PARTNERasp oder DATEV SmartIT nutzt
Der Ablauf der Einrichtung ist hier beschrieben: DATEVconnect on-premises einrichten
Systemvoraussetzungen OCT
OCT Applikation 5.11 oder höher - je nach Einrichtungsvariante lokal oder in der Azure Cloud
OCT Datenbank
eine OCT Datenbank als Zieldatenbank muss on-prem oder in einer Cloudumgebung erreichbar sein
Technische Einrichtung
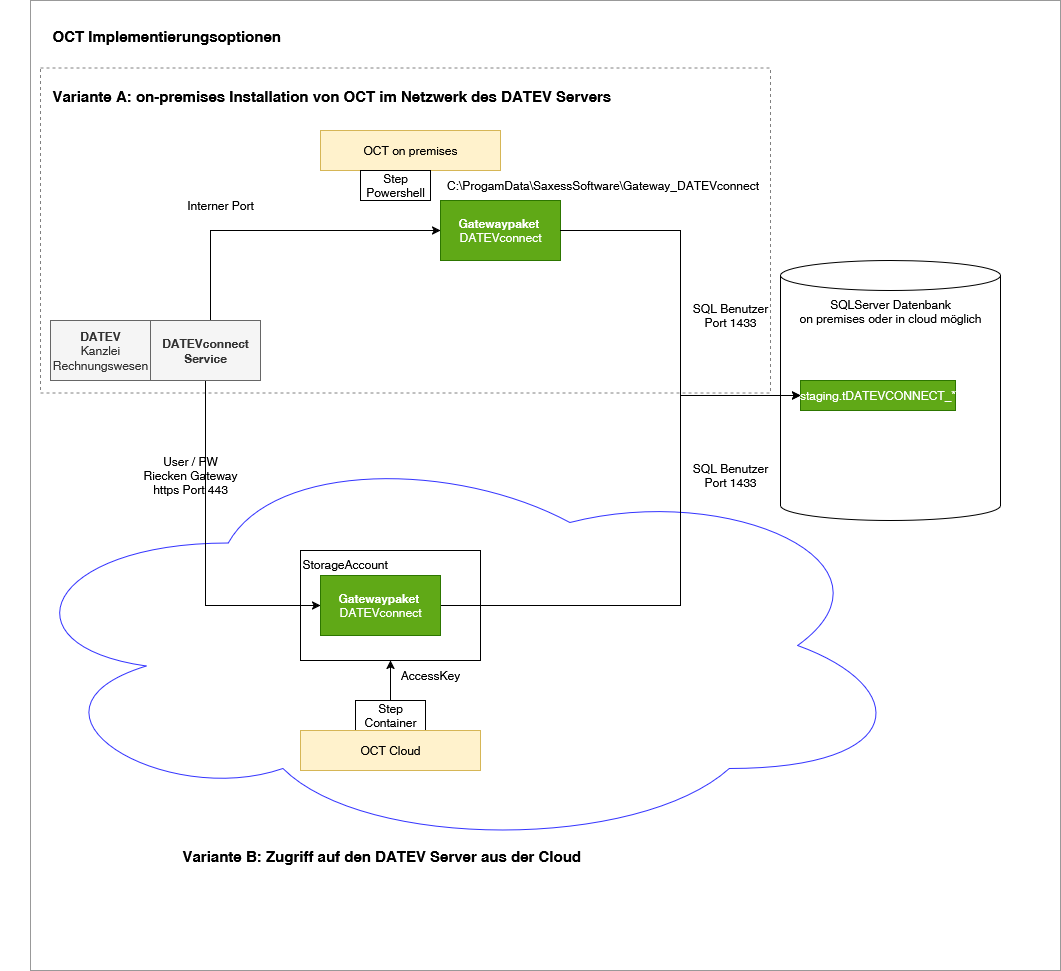
Variante A: on-premises Installation von OCT im Netzwerk des DATEV Servers
Richten Sie eine lokale Python Umgebung für die Ausführung von OCT Gatewaypaketen ein
Den Releaseordner herunterladen, entpacken und nach C:\ProgramData\Saxess Software\Gateway_DATEVconnect kopieren (bei anderem Pfad muss der Aufrufbefehl im Step angepasst werden)
Datenbankobjekte durch Ausführen des Scripts “Datenbankobjekte_Gateway_DATEVconnect.sql” aus dem Ordner “setup” des Gatewaypakets einspielen
Die Zertifikatsdatei für DATEVconnect welche beim Schritt “Systemvoraussetzungen” exportiert wurde, unter C:\ProgramData\Saxess Software\DATEVconnect ablegen
Die “config.json” Datei im Ordner config des Gatewaypakets bearbeiten
Zertifikatspfad hinterlegen
Datenbankverbindung
globales Startjahr für den Abruf der Wirtschaftsjahre
DatenquellenID = beliebige ID (da man mehrere DATEV Systeme an eine OCT Datenbank anbinden kann)
optional: testweise Direktausführung
Python Script main.py im Modus 1 ausführen, um die Steuerungstabelle des Gateways aufzubauen per “1_Steuerungstabelle aktualisieren.bat”
Steuerungstabelle konfigurieren → manuell oder mit Script Gatewaysteuerung.sql
Das Python Script in Modus 2 ausführen, um die Daten zu lesen per“2_Daten abrufen.bat”
die Konfiguration der Pipeline erfordert das editieren von Steps des Typs Powershell - dies ist nur für Administratoren des OCT Servers möglich. Anwender, welche diese Konfiguration bearbeiten können sollen, benötigen somit die Rolle Serveradmin der OCT Instanz (Adminrechte in der Datenbank reichen nicht)
Pipeline RUNME einrichten
globalen Parameter “DatenquellenID” an der Pipeline definieren → DatenquellenID eintragen
Steps für die Ausführung über Container löschen

Step 1 einzeln ausführen (nur diesen allein !) → dieser baut die Steuerungstabelle auf
Step 2 anpassen → Mandanten und Jahre definieren, welche übernommen werden sollen, dann per “Ausführung testen” testweise ausführen
Step 3 ausführen → ruft die Daten ab
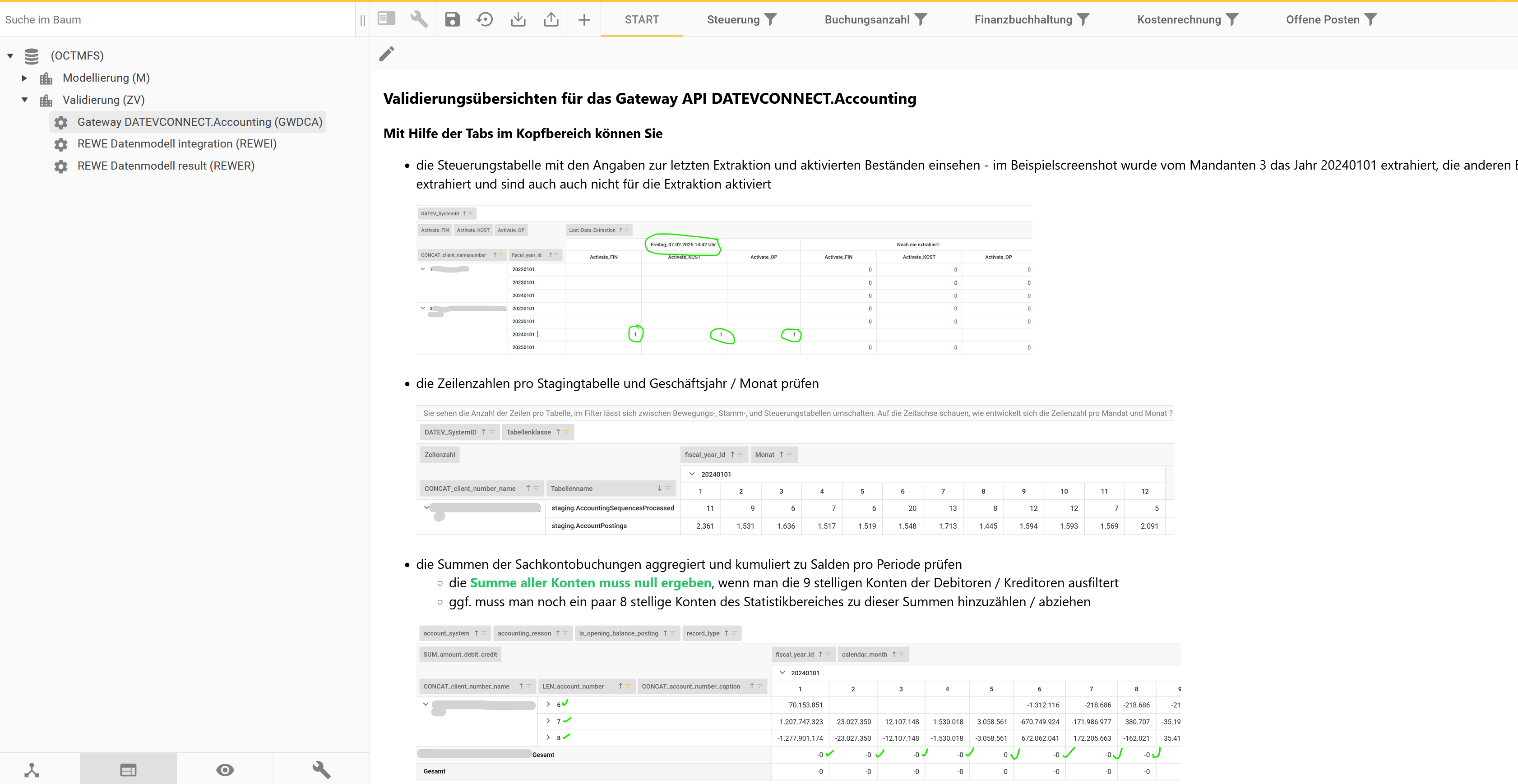
Datenvalidierung in OCT über die Factory ZV, Productline Staging DATEVconnect.Accounting
Variante B: Zugriff auf den DATEV Server aus der Cloud
Einen Storage Account vom Typ FileStorage als Datenquelle anlegen
Datenquelle Azure Storage:
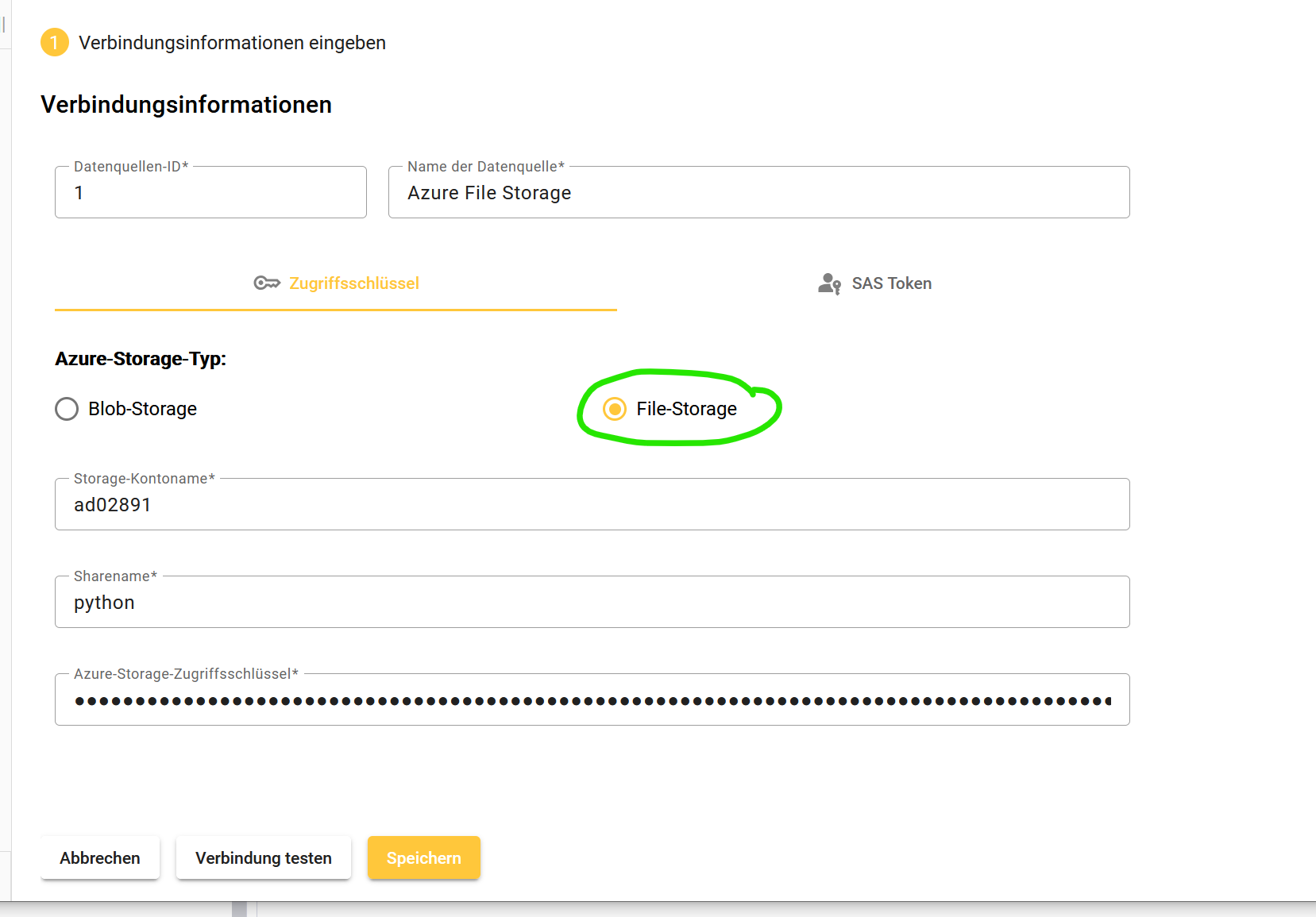
Im Azure Storage Account eine Dateifreigabe “python” (Name sollte so lauten, ist nicht zwingend) mit einem Ordner “scripts” (Name muss so lauten, containerintern wird er referenziert) anlegen
am besten im Azure Storage Explorer, Details und Anleitung siehe Blob Storages für Datenuploads
Den Release Ordner herunterladen, entzippen und den Ordner “Gateway_DATEVconnect” hochladen in den Ordner “scripts”
Datenbankobjekte durch Ausführen des Scripts “Datenbankobjekte_Gateway_DATEVconnect.sql” aus dem setup Ordner einspielen
Die “config.json” Datei im Ordner config bearbeiten
Credentials für DATEVCONNECT
Datenbankverbindung mit SQLUser
globales Startjahr für den Abruf der Wirtschaftsjahre
DatenquellenID = beliebige ID (da man mehrere DATEV Systeme an eine OCT Datenbank anbinden kann)
Pipeline RUNME einrichten
globalen Parameter “DatenquellenID” an der Pipeline definieren → DatenquellenID eintragen.
Diese ist unabhängig von der DatenquellenID unter Datenquelle, sondern steht im Zusammenhang mit der DatenquellenID aus der config.json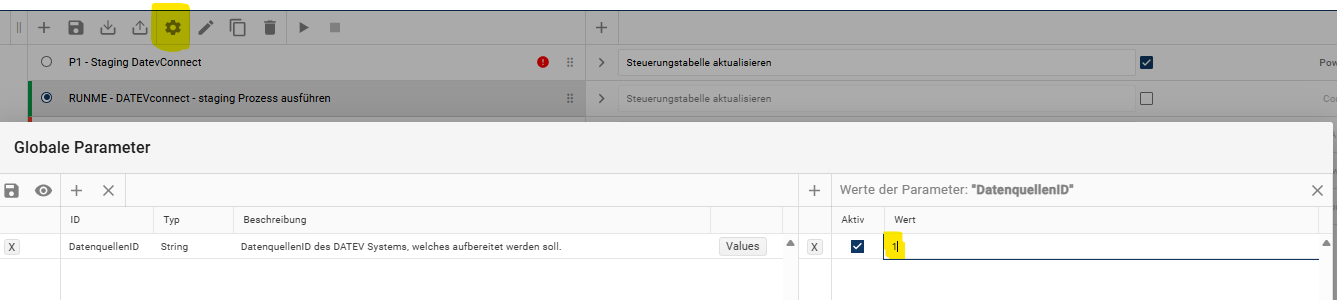
Step 1 in der Powershell Variante löschen (die Containervariante bleibt) → baut die Steuerungstabelle auf
Container einstellen!
Step 2 anpassen → Mandanten und Jahre definieren, welche übernommen werden sollen, dann per “Ausführung testen” testweise ausführen
Step 3 in der Powershell Variante löschen (die Containervariante bleibt) → ruft die Daten ab
Container einstellen!
Datenvalidierung in OCT über die Factory ZV, Productline Staging DATEVconnect
Fachliche Einrichtung
Der Datenbestand umfasst mehrere Abschlussarten, über das Feld accounting_reason der Tabelle staging.tDATEVCONNECT_AccountPostings muss eine passende Kombination gefiltert werden
Handelsbilanz = independent_from_accounting_reason + commercial_law
Steuerbilanz = independent_from_accounting_reason + tax_law
Andere Abschlussarten =independent_from_accounting_reason + reserved1 .. x etc.
Die Periode muss aus der Bezeichnung des Buchungsstapels ermittelt werden - nicht aus dem Buchungsdatum.
Offene Posten liegen jahresweise vollständig vor - es darf also nur der Bestand des letzten Geschäftsjahres für die Auswertung des Bestandes der aktuell offenen Posten herangezogen werden.
Hinweise
Buchungen der Kostenrechnung sind nur sehr eingeschränkt abrufbar
Buchungen mit Verteilschlüsseln https://apps.datev.de/help-center/documents/1000873 sind nicht abrufbar, sie werden nur zu Laufzeit berechnet (ggf. Selbstberechnung durch OCT AddOn möglich)
Direkt gebuchte KOST Stapel sind lesbar
Umlageberechnungen sind nicht lesbar
es gibt client_id und client_number zur Identifikation vom Mandanten
die client_id ist der eindeutige Schlüssel
die client_number kann in der Tabelle Clients eine andere sein als in der Tabelle Fiscal Years (bei clients ist es die Firmennummer, bei FiscalYears die Mandantennummer)
Allgemeine Aufbereitungsgrundsätze
Alle Daten beziehen sich auf einen Client (Mandant) und ein Fiscal Year (Wirtschaftsjahr)
Der Client kann pro Jahr zu einem anderen Consultant (Berater) gehören
Innerhalb eines DATEV Systems ist die Client_id immer eindeutig, bei Zusammenführung mit anderen DATEV Systemen wahrscheinlich auch
Der Client kann pro Fiscal Year
den (Kontorahmen) wechseln
die (Kontonummernlänge) wechseln
den Geschäftsjahresbeginn wechseln
sofern so ein Wechsel passiert, nennen wir das einen Strukturbruch
die Konstallation seit dem letzten Strukturbruch nennen wir die aktuelle Struktur
man kann die Daten des Clienten somit
für Perioden ohne Strukturbruch getrennt aufbereiten - mehrere technische Mandanten bilden
die Strukturbrüche bei der Aufbereitung behandeln und in die aktuelle Strukturversion überführen
Abrufsteuerung
Steuerungsaufruf
alle verfügbaren clients mit ihren fiscal years werden ermittelt und in eine Steuerungstabelle geschrieben
In der Steuerungstabelle werden die gewünschten fiscal years aktiviert (via SQL, bspw. Step SQL)
Datenabzug
Die aktivierten fiscal years werden im Datenbestand gelöscht und neu geschrieben
Löschaufruf
Alle Stagingstabellen werden per TRUNCATE vollständig löschen
Zusatzanforderungen der Datenaufbereitung
Bewegungswerte für abweichende Eröffungswerte berechnen - durch die Abbildung separater Bestände pro Geschäftsjahr, können die Bewegungswerte pro Konto unvollständig sein. Das Bilanzkonto 1000 könnte in Geschäftsjahr 1 mit einem Endsaldo von 300 enden um im Geschäftsjahr 2 mit einem Eröffnungswerte von 200 starten. Beispielsweise, weil das Konto im neuen Geschäftsjahr auf zwei Konten aufgeteilt wurde. Es fehlt daher im Konto 1000 eine Bewegung -100 für den Import in Controllingssoftware (z.B. CP), welche einen kontinuierlichen Strom von Bewegungswerten erwartet
IC Mapping über Personenkonten
Umgliederung debitorischer Kreditoren / kreditorischer Debitoren
Abbildung mehrerer Abschlussarten (Handelsbilanz / Steuerbilanz)
Aufbereitungsweg Offene Posten (OP)
Dimension Debitoren
Dimension Kreditoren
Einzelbuchungen auf OPs
Posten, welche offen bleiben, werden im nächsten Jahr immer wieder neu eröffnet !
auch dann, falls sie abgeschrieben werden ?
werden beim Ausgleich in 2025 auch die historischen Zeilen von 2022-2024 auf ausgeglichen gesetzt ?
für den aktuellen Bestand liest man daher nur das letzte Jahr
um den Bestand per historischem Stichtag aufzulösen, muss man wahrscheinlich die Zahlungsreihe aufsummieren und nicht über das is_cleard Kennzeichen gehen
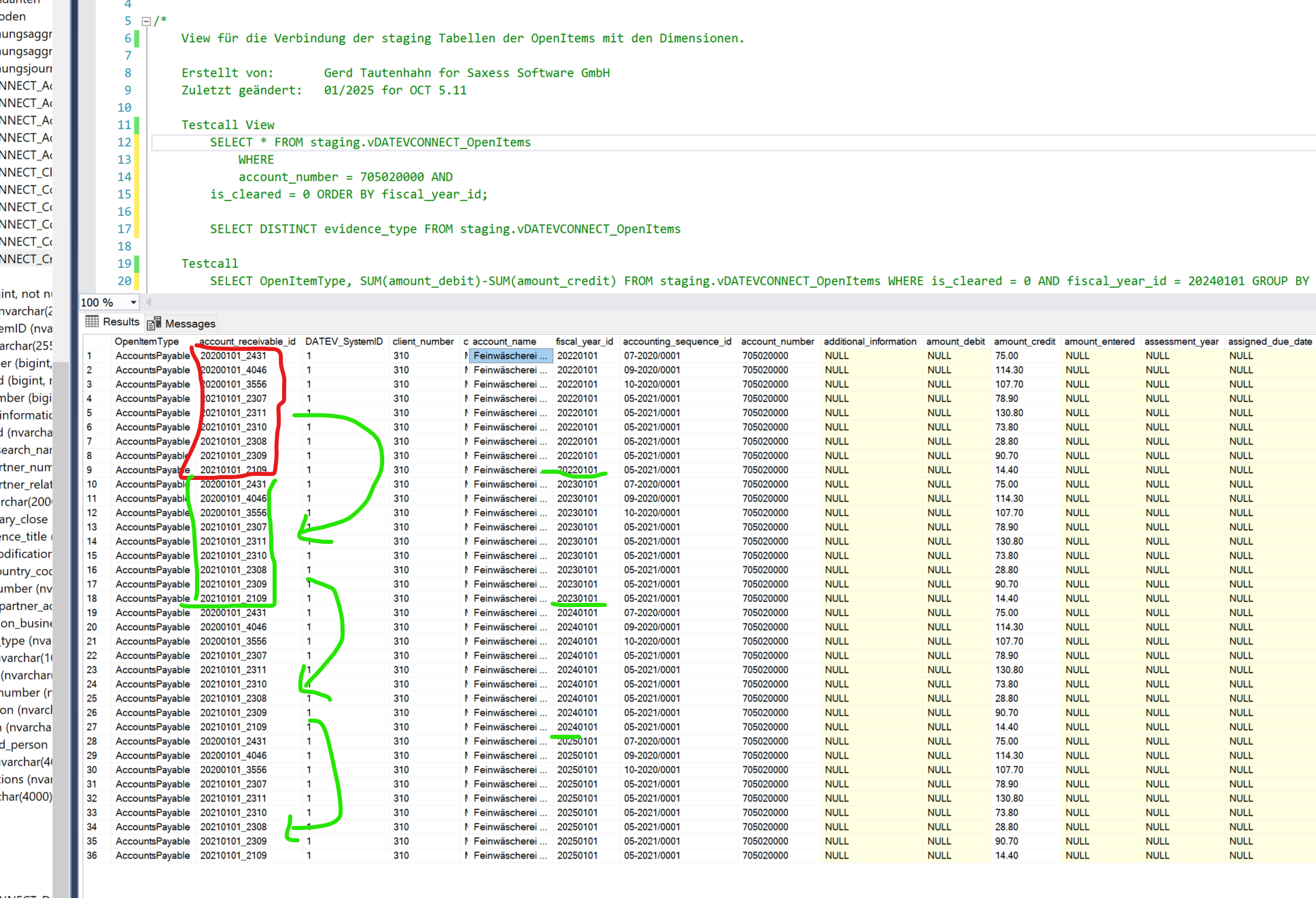
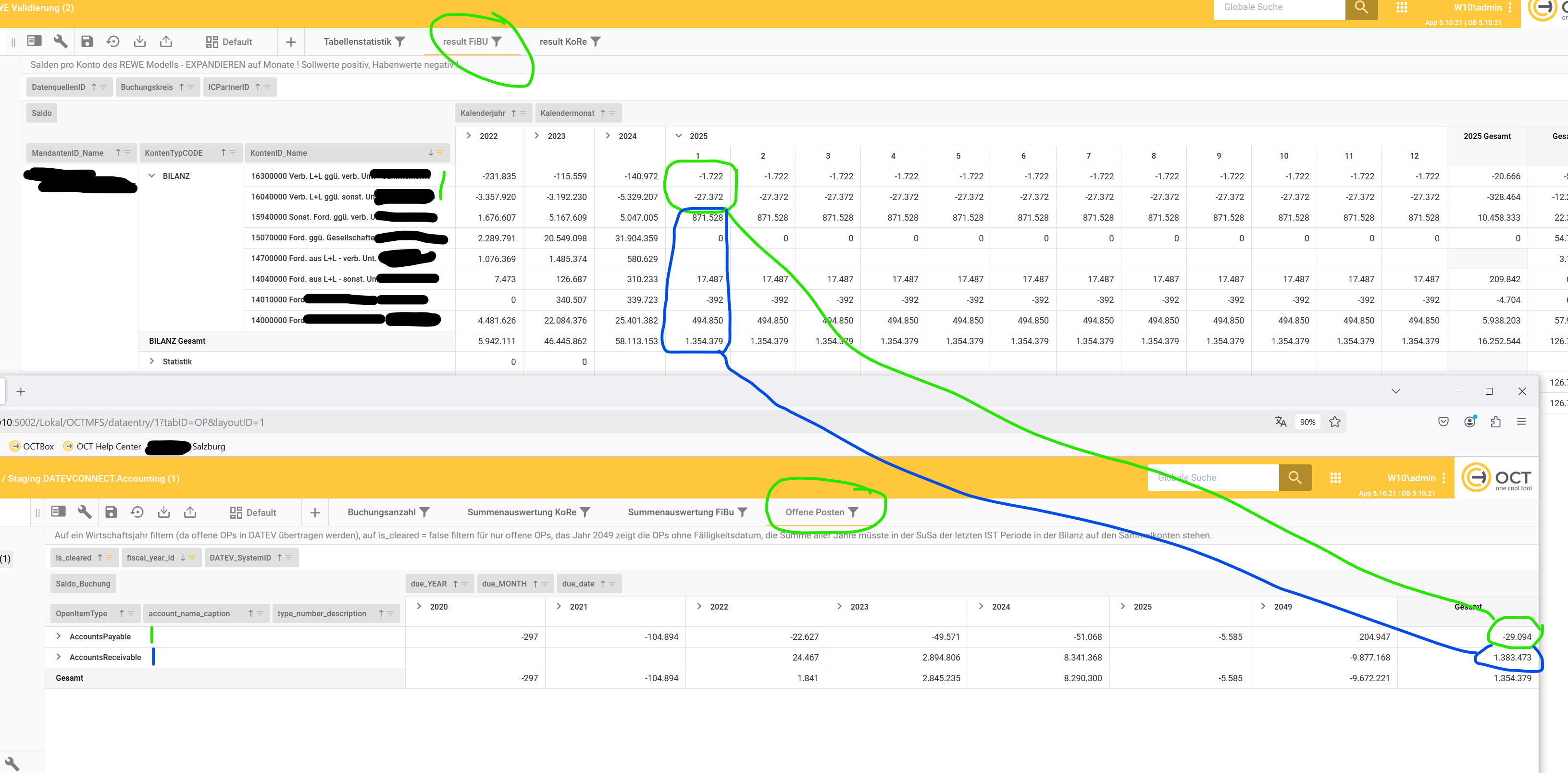
Validierung: die Summe der offenen Posten des letzten Finanzjahres muss dem aktuellen Wert in der letzten IST Bilanzperiode der Summen- und Saldenliste entsprechen
Aufbereitungsweg Anlagenbuchhaltung
Inventarwerte
keine Bewegungswerte
Expertenwissen
Konfiguration der Batchgröße
config.json bearbeiten
api_financialaccount_batchsize - default: 10.000.000 für bis zu 100.000 Buchungen pro Mandant und Jahr
dieser Parameter steuert die Blockgröße beim KontoVon / KontoBis Abruf der Sachkontobuchungen - nur ändern falls Abbruch mit default
da alle Konten 8 stellig sind, somit von 1 bis 99.999.999 abgefragt werden muss, ist die Batchsize recht groß
die Anzahl der Request sollte klein sein (insbesondere bei Cloudrouten mit hoher Latenz), die Datenmenge pro Batch darf aber nicht zu groß werden
Anpassung auf 1.000.000 für bis zu 2 Mio Buchungen pro Jahr
Anpassung auf 100.000 für mehr als 2 Mio Buchungen pro Jahr
api_debcredaccount_batchsize - default: 100.000.000 für bis zu 100.000 Buchungen pro Mandant und Jahr
dieser Parameter steuert die Blockgröße beim KontoVon / KontoBis Abruf der Personenkontobuchungen - nur ändern falls Abbruch mit default
hier muss von 9 stellig abgefragt werden, von 100.000.000 bis 999.999.999
Anpassung auf 10.000.000 für bis zu 2 Mio Buchungen pro Jahr
Anpassung auf 1.000.000 für mehr als 2 Mio Buchungen pro Jahr
DATEV Zusatzinformationen
An einer Buchung können Zusatzinformationen hinterlegt werden. Dies ist ein variables Feld für bis zu 20 Zusatzinformationen, welche in Form eines JSON Arrays von DATEVconnect ausgegeben werden.
Diese Ausgabe erfolgt nur, falls das Buchungsjournal mit dem parameter expand=all abgerufen wird.
Ein vorbereiteter, aber kundenspezifisch zu modifizierender View löst diese Zusatzinformationen auf und stellt diese als eigene Spalten dar.
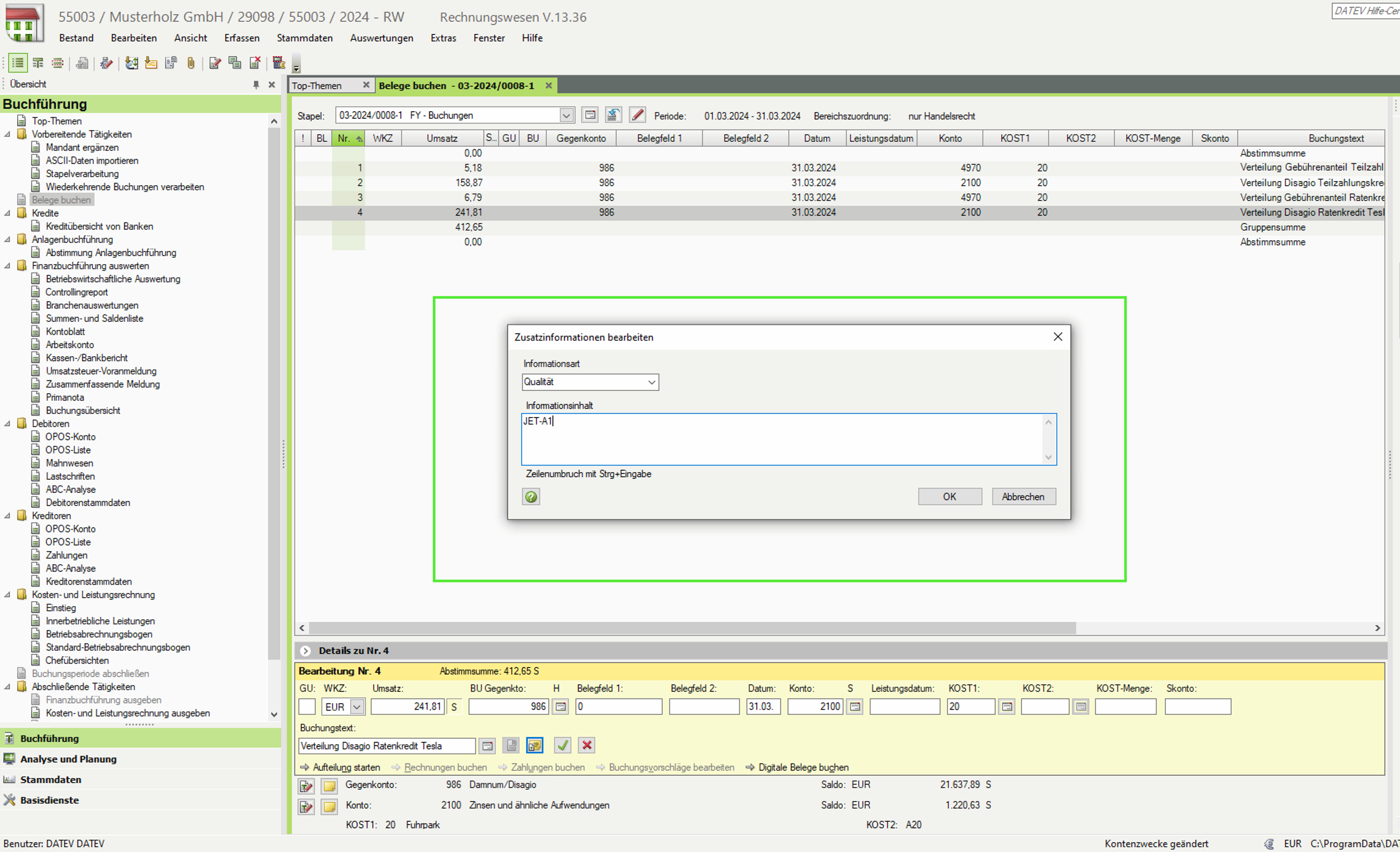
Extraktion der Daten aus mehreren DATEV Systemen
Es können mehrere Systeme extrahiert werden, hierfür werden mehrere config Dateien im config Ordner angelegt.
Dann kann dem main.py Script der Namen der config Datei als Parameter mitgeben werden.
python main.py --modus=2 --configfile=”configDATEV1.json”
python main.py --modus=2 --configfile=”configDATEV2.json”