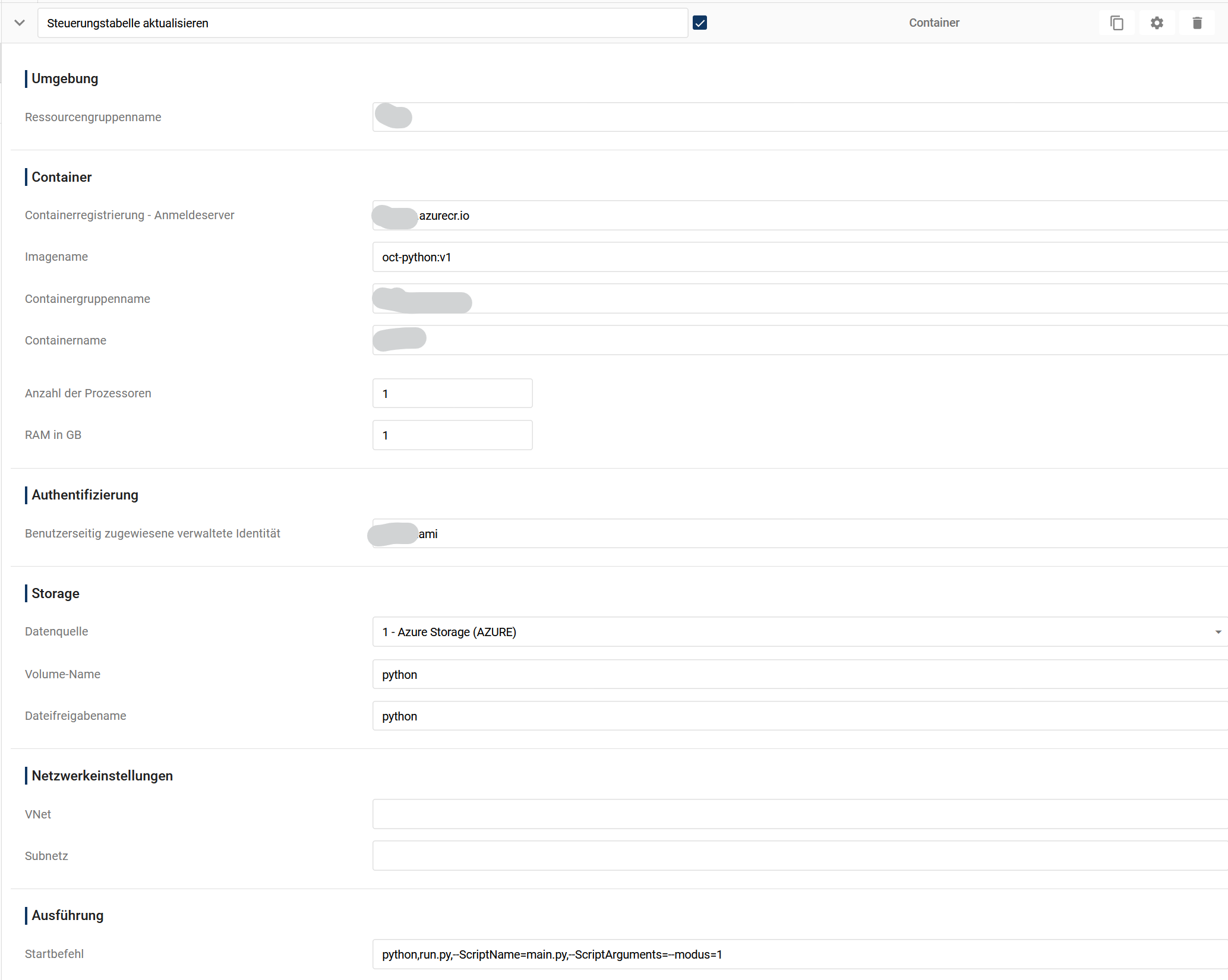
REWE Fachmodell mit DATEVconnect Gateway
Dieses Paket umfasst
das REWE Fachmodell (Ziel Datenmodell, auf welches der Anwender zugreift)
Den Konnektor um die Daten aus der DATEVCONNECT Staging Schicht in das REWE Fachmodell zu laden
das Gateway für DATEVconnect (der “Stecker” um die Daten der DATEVconnect API in die staging Schicht zu laden)
Hier ist primär die Einrichtung mit einer on-premises Installation von OCT beschrieben, die Abweichungen beim Betrieb mit einer OCT Cloud Instanz sind zwischendurch in blau kommentiert und am Ende beschrieben.
Grundsätlich kann das Paket (Fachmodell mit Konnektor und Gateway) eingespielt werden, oder die Komponenten Fachmodell, Konnektor und Gateway einzeln. Der einzige Unterschied liegt in der Anzahl der Pipelines, welche entstehen. Das Paket legt sich eine einzige Pipeline “RUNME” an, die Einzelkomponenten jeweils einzelne Pipelines, deren Steps dann noch zu einer RUNME Pipeline zusammengeschoben werden sollten.
Mindestversion von OCT | v5.11 |
Saxess interne Ressourcen | |
Download |
1. Systemvoraussetzungen
OCT Installation mit einer neuen OCT-Datenbank
vom Server mit der OCT Installation muss die URL des DATEVconnect Webservice erreichbar sein
Falls DATEV on-premises betrieben wird ist daher im Normalfall auch eine on-premises Installation von OCT notwendig
nur falls der DATEVconnect Webservice über eine Drittanbieterkomponenten (Riecken) öffentlich verfügbar gemacht wird, kann auch eine Cloud Instanz von OCT genutzt werden
Zugangsdaten zur DATEVconnect API müssen vorhanden sein:
URL
Zugangsvariante on-premises: ein Windows Benutzerkonto mit DATEVconnect Rechten ist vorhanden
Zugangsvariante Cloud: Benutzername und Passwort sind bekannt
Eine Python Installation muss vorhanden sein (entfällt bei OCT Cloud Nutzung)
Eine lokale Installation von VisualStudioCode sollte vorhanden sein (entfällt bei OCT Cloud Nutzung)
2. Installation
Paket DATEVconnect.zip über den Downloadlink oben herunterladen und entpacken.
Den entpackten Ordner “DATEVconnect” ablegen unter C:\ProgramData\Saxess Software\DATEVconnect (anders bei OCT Cloud, siehe Punkt 7)
Der Ordnername sollte exakt so lauten, andernfalls müssen die Aufrufpfade in den Pipelinesteps angepasst werden.
Diese Order “DATEVconnect” beinhaltet:
Order setup: Enthält alles für die Installation
Ordner log: dieser Ordner wird automatisch erzeugt, hier werden die Logdateien bei der Ausführung abgelegt.
Ordner config: Beinhaltet die zentrale Konfigurationsdatei (config File), auf die welche die Extraktionsskripte zugreifen.
*.bat-Dateien: Zwei Batch-Dateien, mit denen der API-Abruf ins Staging auch ohne OCT getestet werden kann.
*.py-Dateien: Python Script für die Datenextraktion
versionsinfo.txt: Eine Textdatei mit Versionsinformationen.
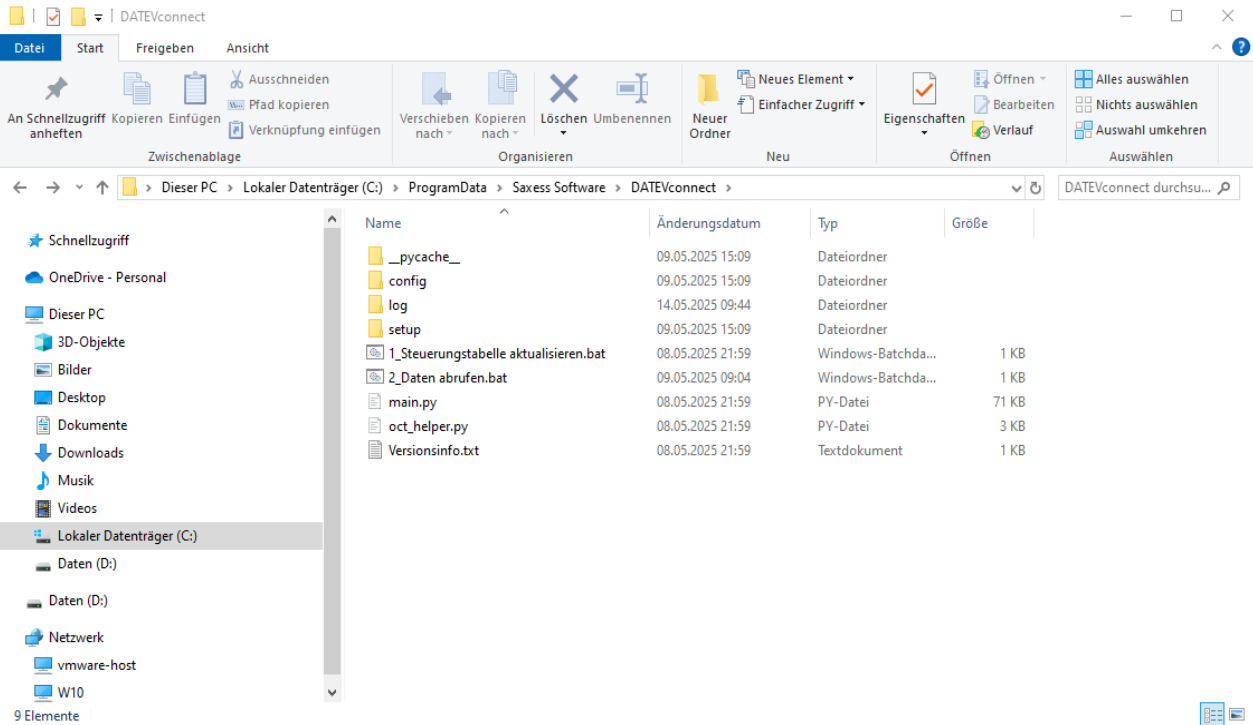
öffnen Sie aus dem Ordner config die Datei config.json und erfassen Sie dort
Customer: beliebige Bezeichnung für den Kundennamen
datev_system_id: Kennung für das DATEVSystem - wird in OCT als DatenquellenID verwendet Defaultwert “DATEV”
start_fiscal_year_id: ab diesem Wirtschaftsjahr wird der Bestand zur Verarbeitung angeboten (kann später noch pro Mandant eingeschränkt werden)
api_username: leer bei on-premises, Username falls Zugriff aus Cloud
api_passwort: leer bei on-premises, Username falls Zugriff aus Cloud
api_winauth: 0 für Cloud, 1 für on-premises
legen Sie das Zertifikat für den DATEVconnect Webservice im Ordner “DATEVconnect” als datevconnect.cer ab (entfällt bei Cloud)
Wichtig ist, darauf zu achten, dass sich keine versteckten Leerzeichen oder sonstige Formatierungsfehler einschleichen, die den JSON ungültig machen.
Das Skript liefert in diesem Fall keine detaillierte Fehlermeldung – außer, dass das CONFIG-File im angegebenen Pfad nicht gefunden wurde.
Der eigentliche Fehler liegt dann aber meist an einem Formatierungsproblem im JSON selbst. In Passwörtern / Pfadangaben müssen Sonderzeichen ggf. per \ escaped werden bzw. vorhandene \ verdoppelt werden.
3. Einspielen des REWE Moduls incl. DATEVconnect Gateway
Anschließend öffnen Sie den Setup Ordner und öffnen SETUP_REWE_DATEVConnect.sql im Management Studio. Das Skript führen Sie in der OCT Datenbank aus.
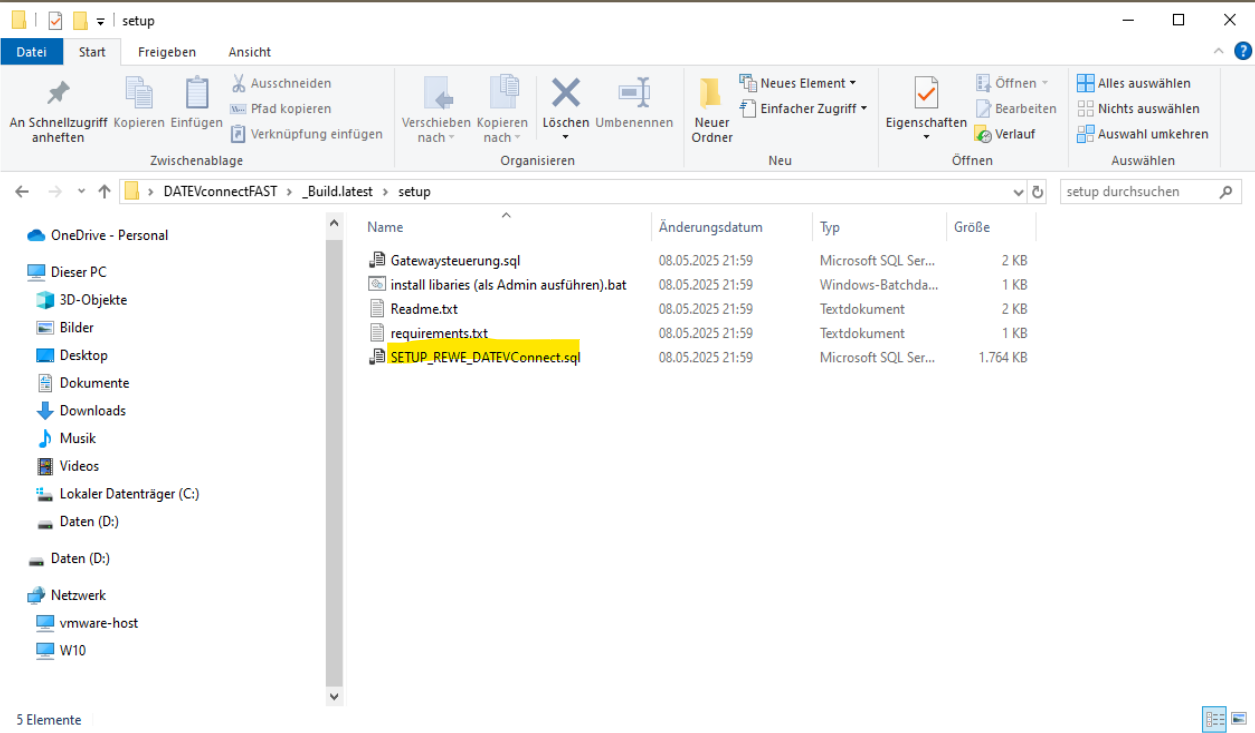
In OCT sollte sich anschließend eine Sammlung an Pipelines aufgebaut haben.
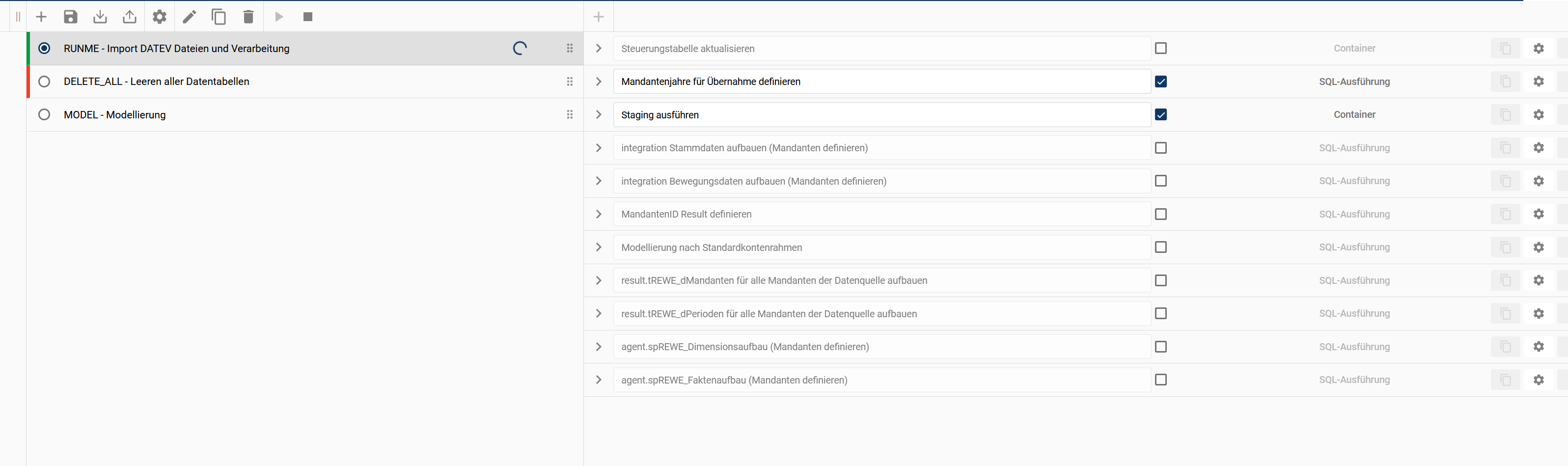
Auch im Datenerfassungsbereich wurden dabei bereits verschiedene Objekte erstellt.
Das REWE Modul incl. DATEVconnect Gateway is erfolgreich in OCT eingespielt.
4. API Abruf testen (optional, nur bei on-prem Installation möglich)
4.1. Steuerungstabelle konfigurieren
Im nächsten Schritt testen wir den manuellen Abruf der DATEV API in das Staging-Schema des Moduls.
Dafür ist zunächst die Installation der notwendigen Python Libraries erforderlich.
Führe dazu die .bat-Datei mit dem Namen “install libraries” aus.
→ Wichtig: Die Datei unbedingt als Administrator ausführen!
Anschließend bearbeiten wir die Steuerungstabelle.
Öffne dafür im setup-Ordner das SQL-File “Gatewaysteuerung” im Management Studio, führe es jedoch nicht vollständig aus.
Mit diesem File können die Mandantenkonfigurationen angepasst werden.
Markiere zunächst nur die erste Zeile und führe diese mit F5 aus, um die Default-Konfigurationen anzuzeigen.
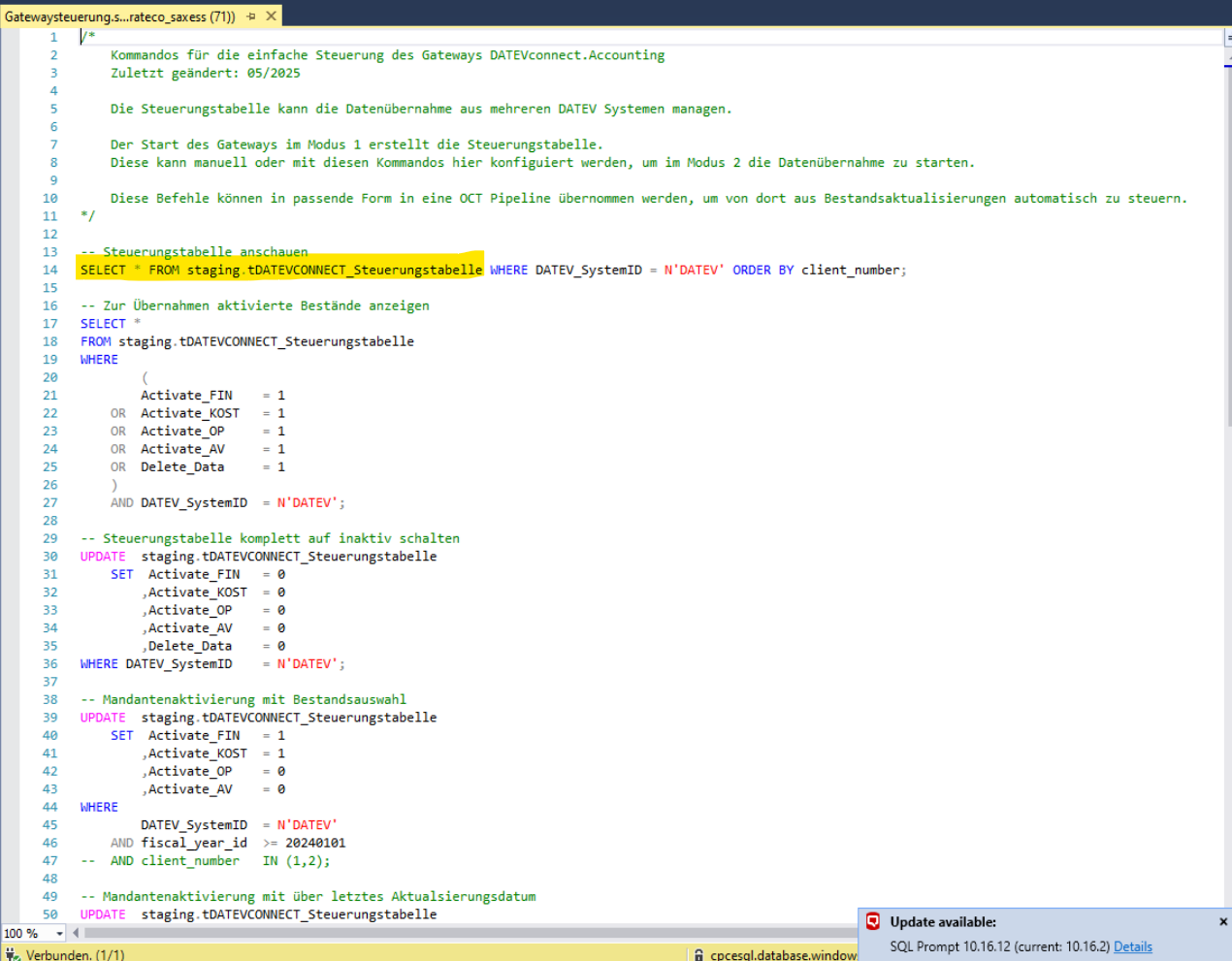
Das sieht wie folgt aus:

Aktivierung der gewünschten Datenbestände zum Abruf.
Relevant ist hier, welche Daten übernommen werden sollen, also ob FIN, KOST, OP, AV.
In unserem Beispiel wollen wir FIN und KOST ab dem 01.01.2023 abrufen, und zwar für beide Mandanten.
Um das zu hinterlegen, gehen wir erneut in das Skript der Gatewaysteuerung zum Punkt "Mandantenaktivierung mit Bestandsauswahl".
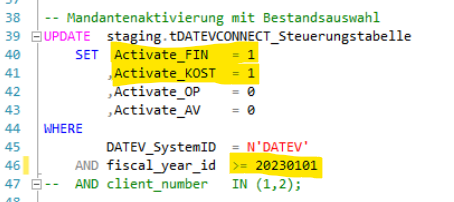
die relevanten Kategorien setzen wir auf 1 und passen das Startjahr der Extraktion an
anschließend markieren wir wieder den relevanten Updatebefehl einzeln und führen mit F5 aus
Nun geben wir mit dem ersten Befehl die überarbeitete Steuerungstabelle aus und prüfen auf Richtigkeit!
4.2. Abruf ins Staging
In der ersten Ebene des Ordners befinden sich zwei .bat-Dateien:
1_Steuerungstabelle aktualisieren.bat
2_Daten abrufen.bat
Diese werden in genau dieser Reihenfolge ausgeführt. Der Vorgang kann durchaus einige Zeit in Anspruch nehmen.
Wenn die Skripte durchgelaufen sind, kann in den Staging-Tabellen überprüft werden, ob die Daten angekommen sind. Andernfalls würde dies auch im Skriptlog entsprechend vermerkt.
→ der initiale Abruf hat funktioniert
5. Modell- und Pipelinekonfiguration in OCT
5.1. Modellierung für Kontorahmen
Damit die Kontenzuordnungen korrekt funktionieren müssen wir als erstes das Datenmodell einpflegen. Das geht über den Datenerfassungsbereich und die Factory Modellierung.
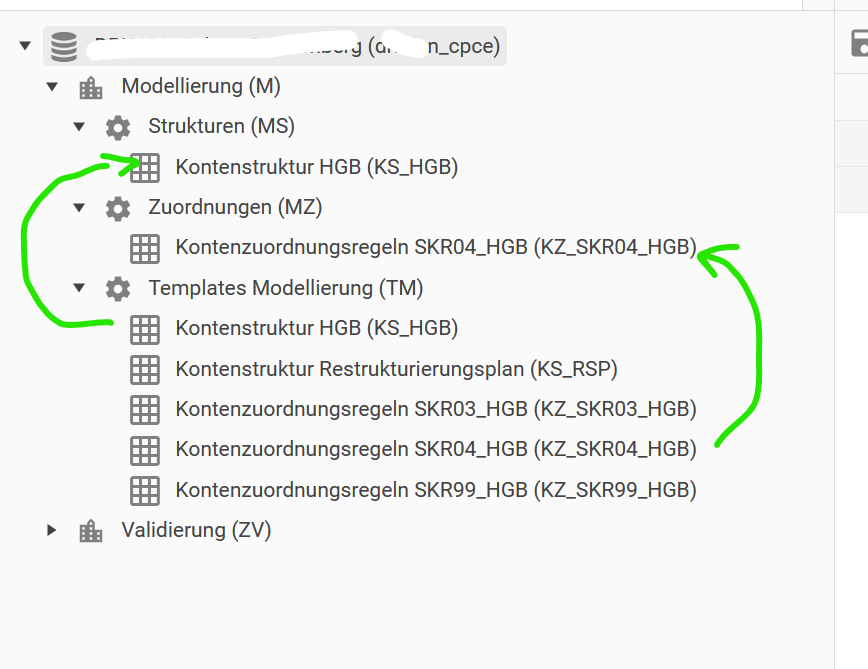
Darin befinden sich die Ordner Productlines, Strukturen, Zuordnungen und Templates.
Aus den Templates kopieren wir als erstes das Product “Kontenstruktur HGB" in den Ordner Strukturen.
Dann kopieren wir den passenden Kontenrahmen aus dem Ordner Templates in den Ordner Zuordnungen.
Welcher Kontenrahmen verwendet wird, lässt sich aus der Steuerungstabelle ablesen, unter dem Feld account_system (siehe Screenshot Steuerungstabelle).
Nachdem die Zuordnung vorgenommen wurde wird die MODEL Pipeline (Schritt 1-3) ausgeführt:
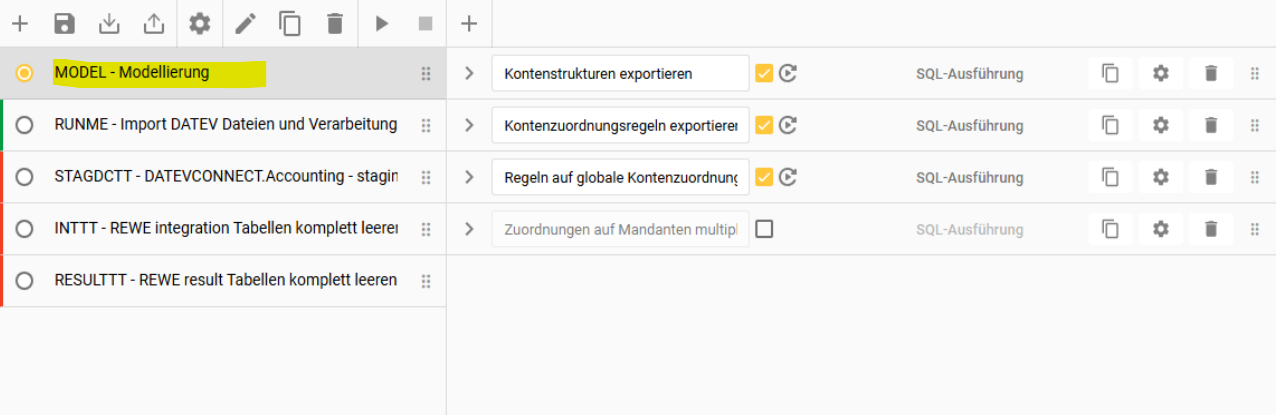
Die Modellierung ist somit abgeschlossen!
5.2. Pipelinekonfiguration
Das Ziel in diesem Schritt ist es, die Importpipeline zu konfigurieren. Diese sorgt dafür, dass der zuvor über die .bat-Dateien getestete Abruf in OCT eingebunden wird und die Daten aus dem Staging-Bereich in die Schemata integration und result überführt werden.
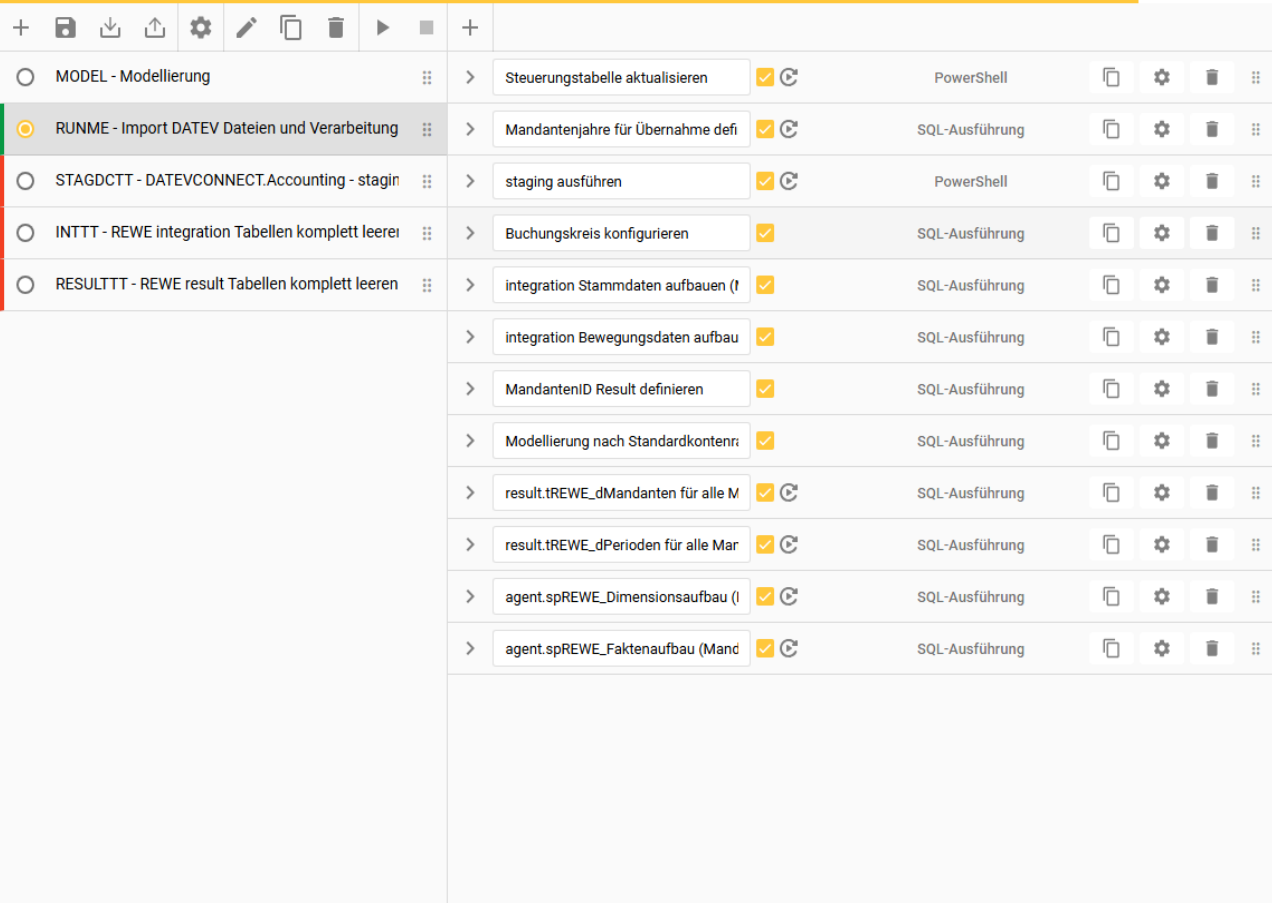
Schritte:
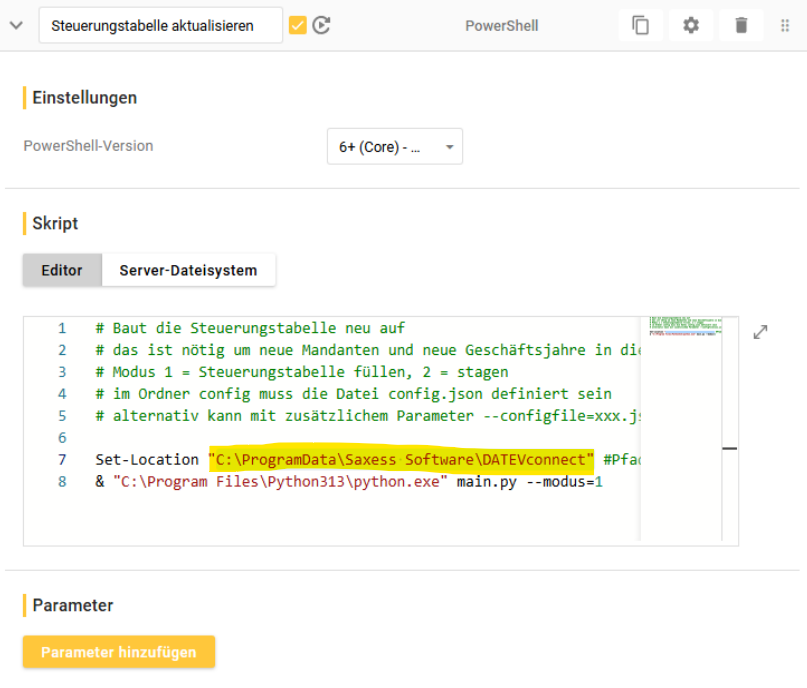
1. “Steuerungstabelle aktualisieren” & “staging ausführen”
hier muss der Pfad des Skriptordners hinterlegt werden
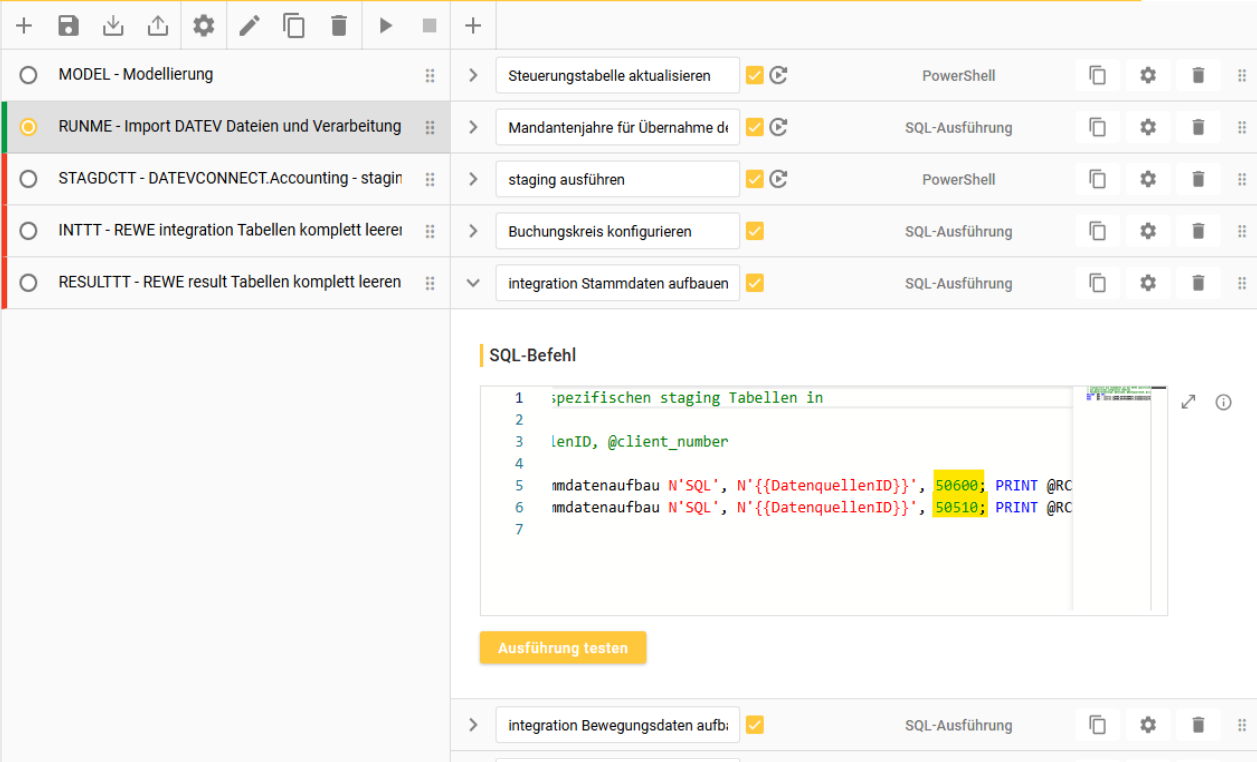
2. “Mandantenjahre für Übernahme definieren”
hier wird die Auswahl zu Extraktionszeitraum und Art der Daten, analog zu der manuellen Steuerungstabelle aus 4.1. hinterlegt
3. MandantenID’s hinterlegen in den Schritten:
“integration Stammdaten aufbauen (Mandanten definieren)”
“agent.spREWE_Dimensionsaufbau (Mandanten definieren)“
“agent.spREWE_Faktenaufbau (Mandanten definieren)“
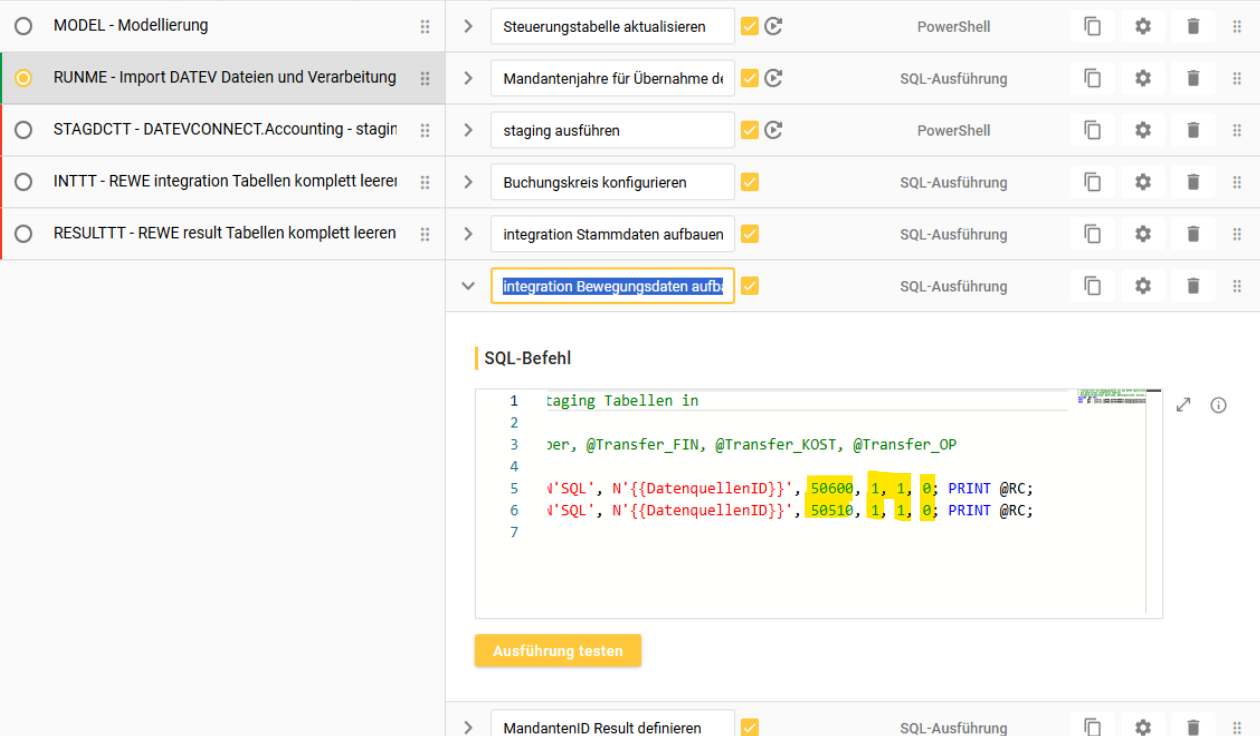
MandantenID und Datentypauswahl ergänzen in “integration Bewegungsdaten aufbauen (Mandanten definieren)”
in diesem Step wird zusätzlich zu der MandantenID noch einmal ausgewählt ob FIN, KOST, OP übertragen wird
wird analog zur Steuerungstabelle ausgefüllt
Nun kann die Pipeline nach dem Speichern ausgeführt werden!
Im Anschluss kann im Bereich Validierung der Import nach integration und result überprüft werden!
Scheduler:
Es ist nur die Pipeline “RUNME” zu schedulen
DELETE_ALL wird nur im Bedarfsfall ausgeführt, wenn alle Datentabellen geleert werden sollen
Pipeline “Model” ist dann auszuführen, wenn in der Modellierung im Datenerfassungsbereich eine Änderung erfolgt is
7. Anpassungen bei Installation für eine OCT Cloud Instanz
zu 1:
es muss ein Storage Account mit einer Dateifreigabe “python” und einem Ordner “scripts” angelegt werden
die Ablage des Ordners erfolgt in diesem Ordner “scripts” des Storage Accounts
das Storage Account wird in OCT als FileStorage registriert
zu 4: entfällt, Ausführung ist nur über Pipeline möglich
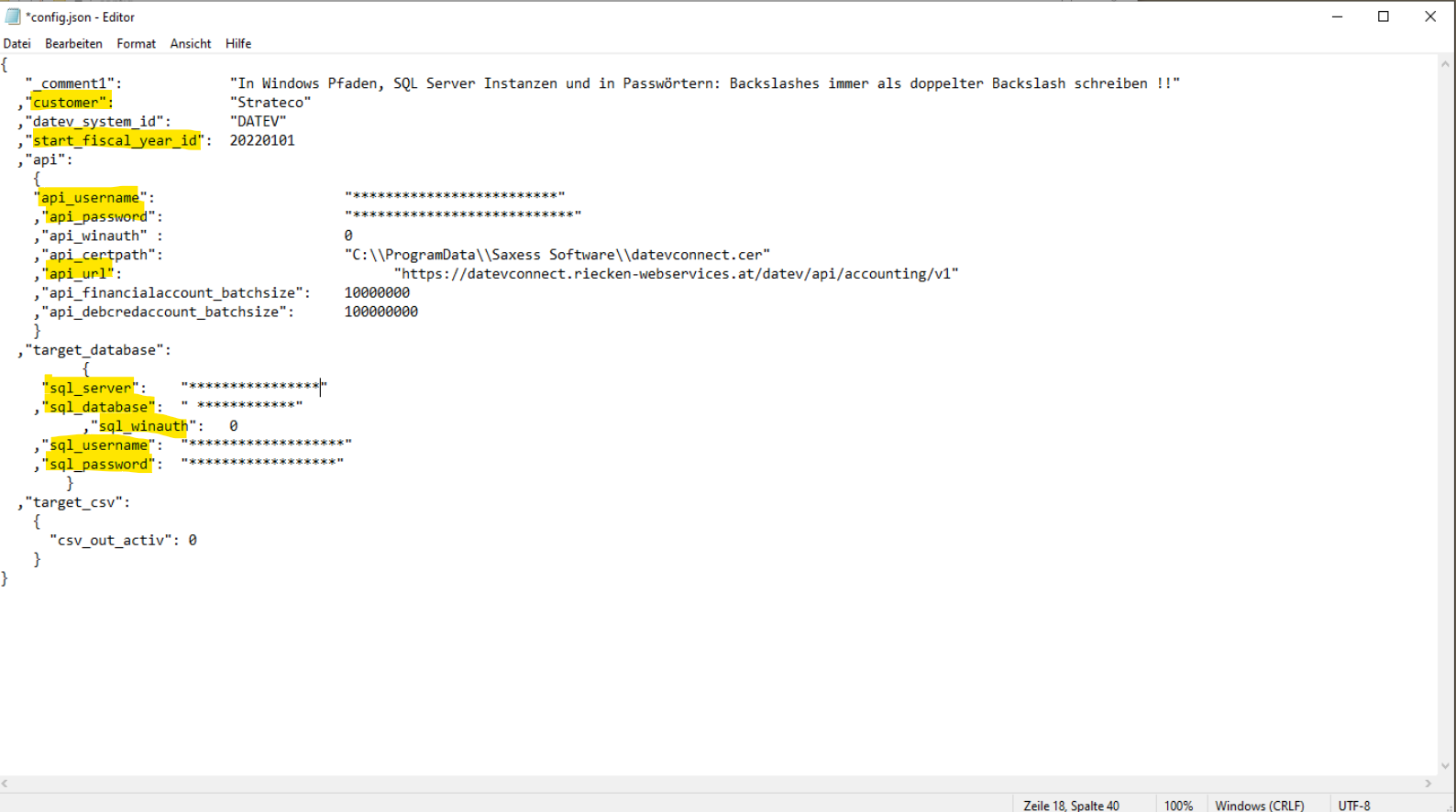
zu 5. die beiden Schritte “Steuerungstabelle aktualisieren” und “staging ausführen” müssen durch Containersteps ersetzt werden. Für die im Screenshot ausgegrauten Bereiche gilt
Ressourcengruppenname: erhalten Sie vom Serverbetreiber
Containerregistrierung: erhalten Sie vom Serverbetreiber
Containergruppenname: AD0xxxxGruppe (AD0xxxx steht für die Kundennummer)
Containername:AD0xxxxDATEVconnect
Identität: erhalten Sie vom Serverbetreiber