DATEV Anbindung mit manuellem Datenexport (Azure Blob Storage & File)
Beschreibt die Extraktion und Weiterverarbeitung von Daten aus DATEV über die DATEV-Schnittstellentechnologie “DATEV AZURE”. Diese Schnittstellentechnologie ist der DATEV-Standard und für alle Anwender ohne DATEV-Zusatzkosten verfügbar.
Der manuelle Export beschreibt das Szenario, falls Sie DATEV auf einem Server von Dritten (z.B. Ihrem Steuerberater) nutzen und dort OCT nicht installieren dürfen/können.
Der Azure Blob Storage wird als alternativer Ablageort für Dateien in der Cloud verwendet, wenn die Dateien nicht auf einem lokalen Laufwerk abgelegt werden können/sollen.
Bei dem File Export wird ein lokaler Ordner als alternativer Ablageort der Dateien verwendet.
Die Anbindung einer KOST.mdb ist aktuell nicht möglich.
1. Anleitung der manuellen Datenextraktion
Richten Sie OCT in einer geeigneten Umgebung ein.
Kopieren Sie die OCT-Exportformate auf den DATEV-Server und spielen Sie diese im DATEV ein.
2. Download und Aktivierung von Modulen, Planungslösungen und Konnektoren
2.1 Aktivierung von Modulen
Laden sie die folgenden Module herunter und aktivieren sie diese:
DATEV-Azure Staging für Finance
Finance
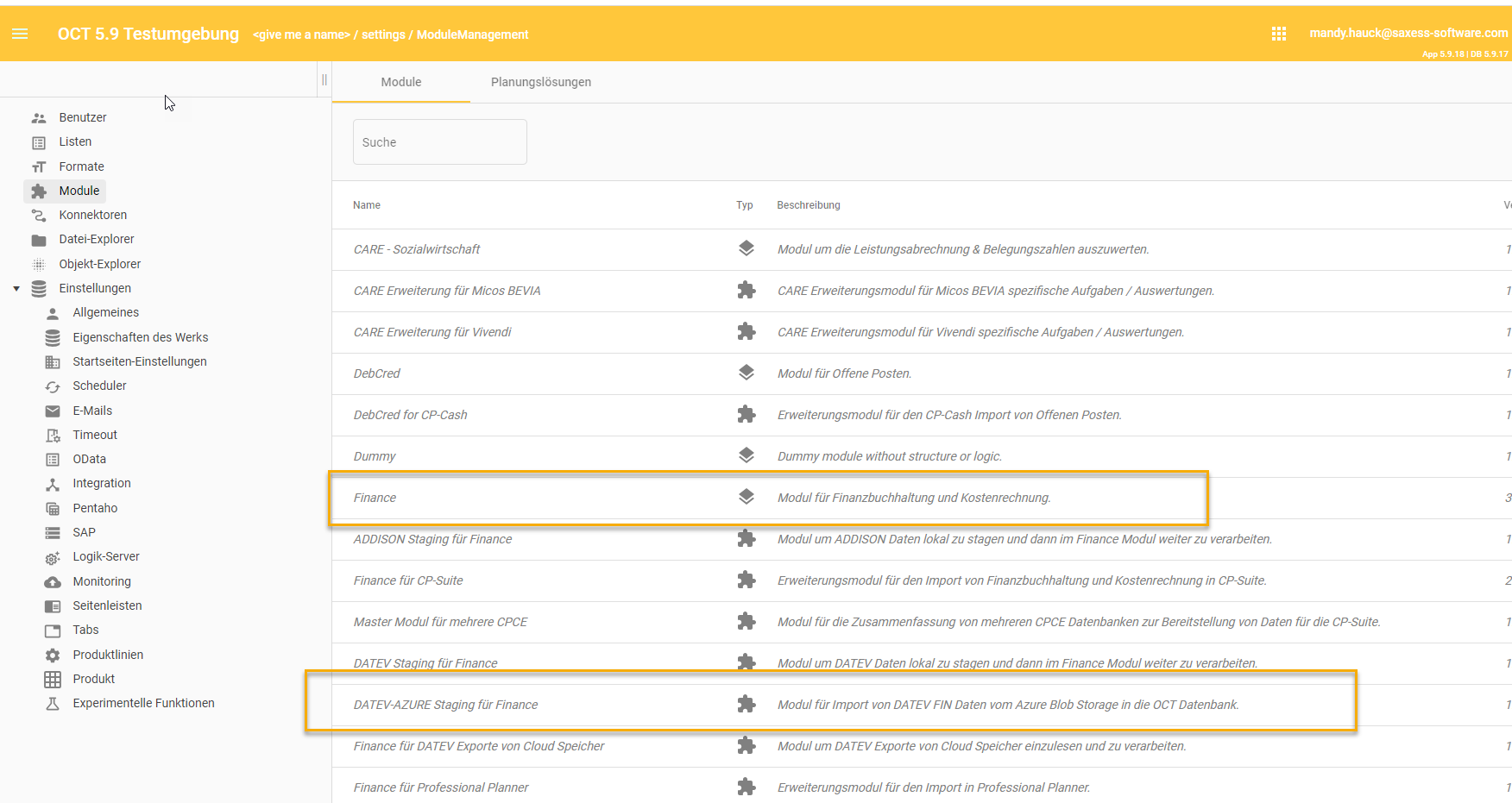
Herunterladen und aktivieren der Module
es wird keine gesonderte Datenquelle angelegt, alles läuft über Datenquelle 0
Modul Finance (FIN) aktivieren (FIN Standardtabellen)
Modul DATEV Azure Staging for Finance (FIN-DATEV-AZURE) aktivieren (lädt DATEV Files per Pipeline Dateiimport in die Staging Tabellen)
2.2 Aktivierung von Konnektoren
Laden sie folgende Konnektoren herunter und aktivieren sie diese:
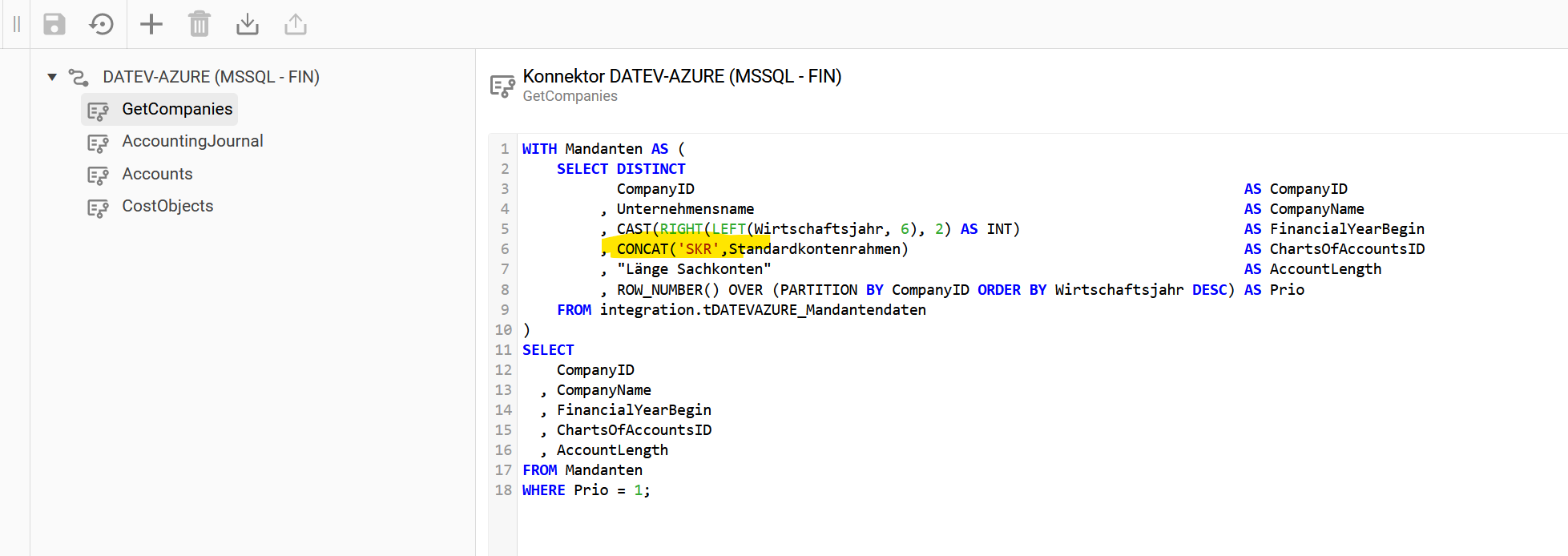
ERP-System: “DATEV-AZURE”, Quellsystemtyp: “MSSQL”, Konnektor: “FIN”
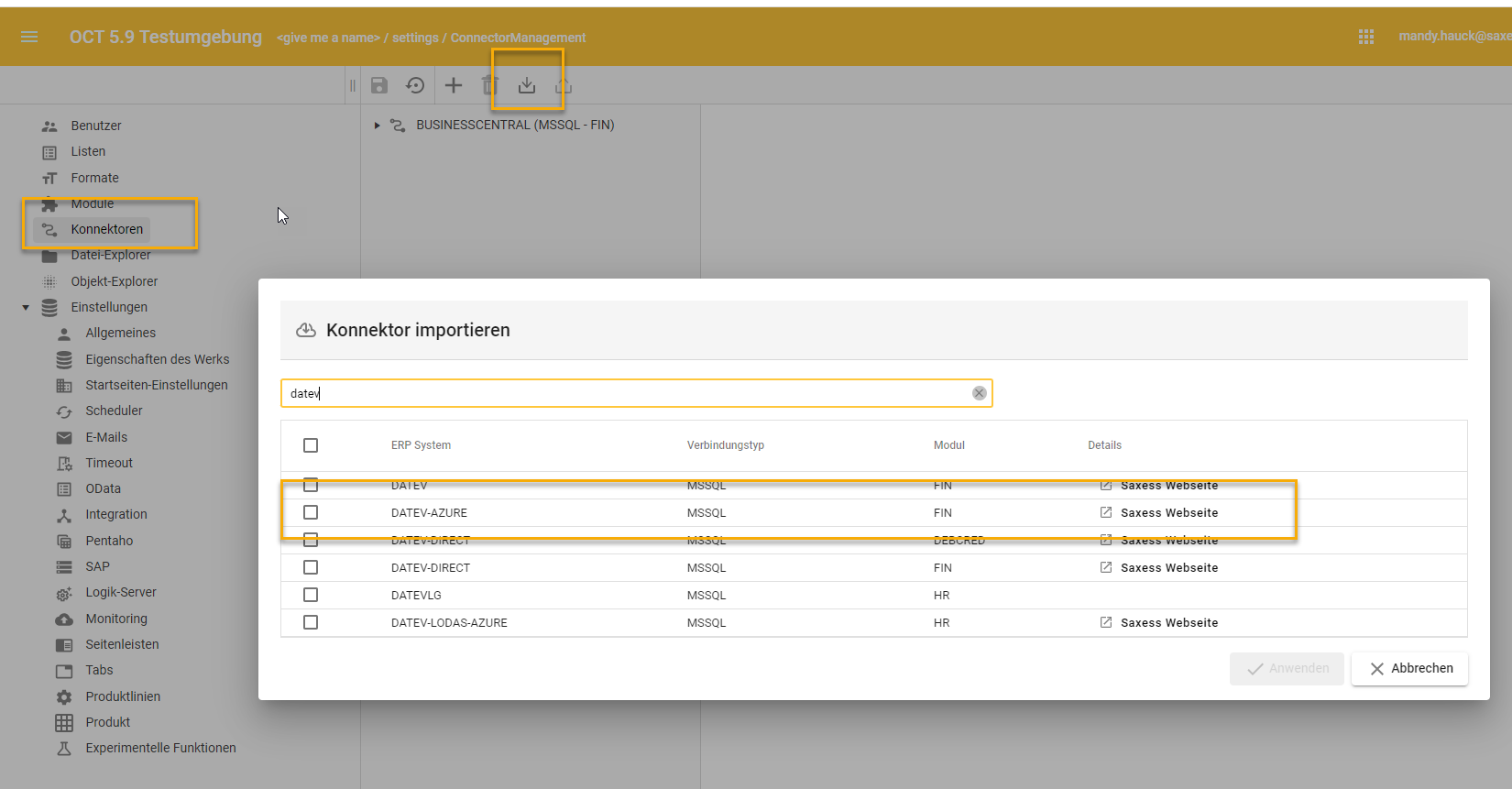
MSSQL Konnektor für DATEV-Azure
Konnektor DATEV-AZURE aktivieren (schreibt integration.DATEV* Tabellen in integration.FIN* Tabellen, erstellt schon vor konfigurierte Prozesspipelines)
3. Dateiquelle einrichten
3.1 Dateiabruf aus Blob Storages
3.1.1 Dateien auf Blob Storage ablegen
siehe https://help.saxess-software.de/sx-cpce-portal/Working-version/blob-storages-fur-datenuploads
Beachten Sie bei der Arbeit mit einem Blob Storages
man kann dort Dateien nicht umbenennen (nur kopieren und löschen der Quelle)
man kann Dateien nicht verschieben (nur kopieren und löschen der Quelle)
am besten daher im das gesamte Verzeichnis zum bearbeiten hoch / runterladen, solange es nicht zu groß ist
es muss immer ein Unterordner angelegt werden (die Dateien dürfen nicht direkt im ersten Ordner des BlobContainers liegen, sonst läuft die Post-SQL-Abfrage in den Pipelinesteps auf Fehler)
im Hauptordner https://help.saxess-software.de/sx-cpce-portal/Working-version/datev-upload
ggf. “Mandantenliste.csv” manuell erstellen (überflüssig, aber ohne diese Datei kennt man Beraternummer / Mandantennummer nicht)
- CODE
Beraternr;Mandantennr;Jahr;Mandantenname; 29098;55003;20200101;Musterholz GmbH; Datei “Beraternr_Mandantennr_Mandantendaten_Jahr.csv muss pro Jahr vorhanden sein - Jahr steht hier für den YYYYMMTT String !
- CODE
Unternehmensname kurz»Unternehmensname»Standardkontenrahmen»Länge Sachkonten»WJ-Beginn»WJ-Ende "ABC GmbH"»"ABC GmbH"»"03"»4»01.01.2022»31.12.2022
Unterordner mit Namen “Beraternr_Mandantennr_MMTT_SKR_KtoLänge” erstellen, zB. 29098_55003_0101_03_4
Kontenbeschriftungen_YYYYMMTT.csv
Kontobuchungen_YYYYMMTT.csv
Kostenstellen_traeger_YYYYMMTT.csv
3.1.2 Konfiguration der Prozesspipelines
Step 1: Import Mandantendaten konfigurieren
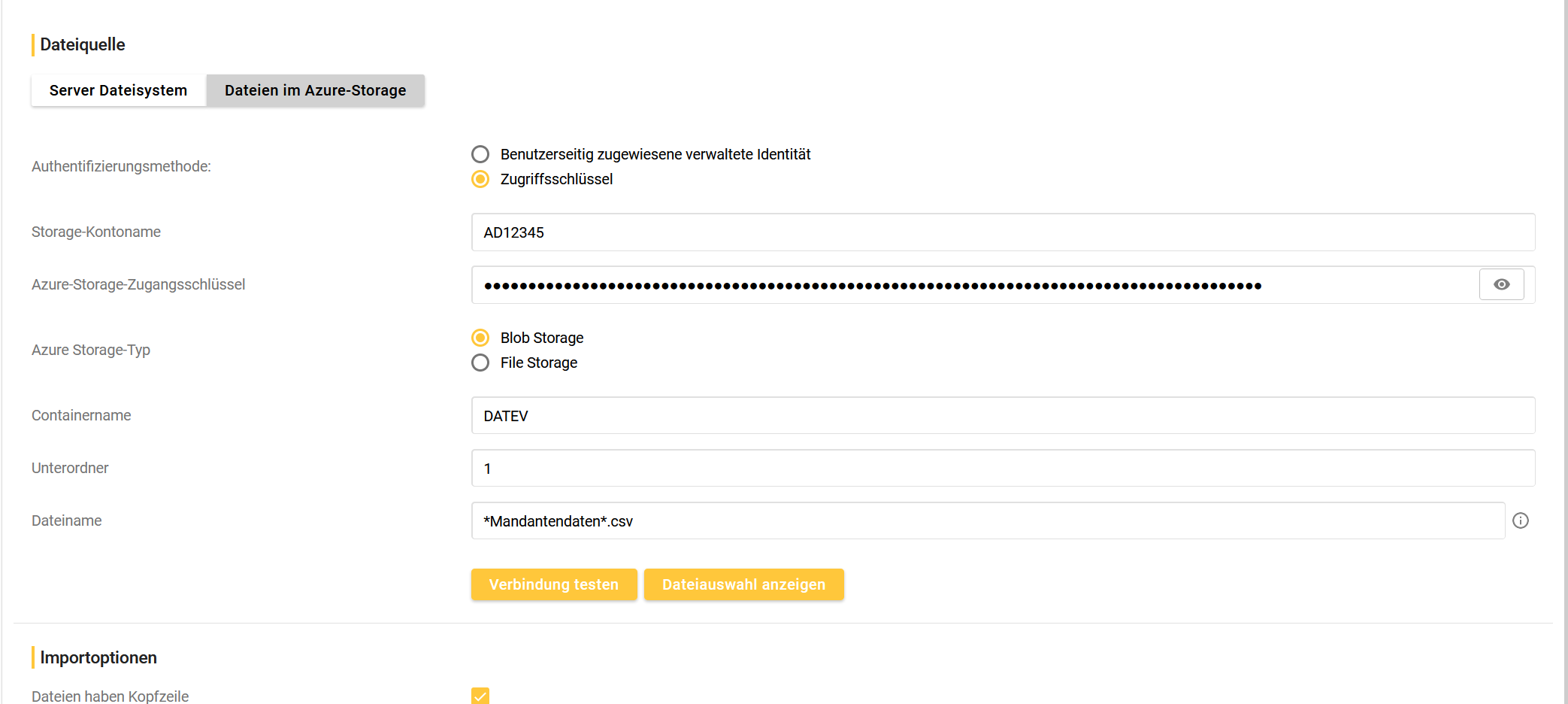
Storage-Kontenname (Storage Account Name): Case sensitiv (Groß-/Kleinschreibung beachten) → den Kontonamen findet man im Microsoft Azure Storage Explorer, wenn man im Baum den Ordner auswählt links unten im Fenster “Eigenschaften”
Azure-Storage-Zugangsschlüssel: der AccountKey aus dem Storage Account Connection String
“Verbindung testen” und per “Dateiauswahl anzeigen” prüfen, ob Dateien gefunden werden (sonst Schreibweise der Dateien prüfen)
Step speichern und aktivieren
Pipeline einmal durchlaufen lassen
Step 2-4:
Import Kontenbeschriftungen, Import Kontobuchungen und Import Kostenstellen_traeger
gleiches Vorgehen wie bei Step 1
Testlauf: die Pipeline muss erfolgreich durchlaufen und die Dateien der Dateien müssen danach in den Tabellen integration.tDATEVAZURE_* stehen
Step SQL Konnektor: aktivieren und Mandanten auswählen
Testlauf: die Pipeline muss erfolgreich durchlaufen und die Daten müssen in den integration.tFIN_ * und global.t* Tabellen stehen
Step Datenbereitstellung aktivieren oder eigenen Datenbereitstellungsprozess implementieren
Testlauf: die Daten müssen danach in den result.t* Tabellen stehen
Fertig, Weiterverarbeitung der Daten je nach Zielsystem
3.2 Dateiabruf aus Server Filedatei
3.2.1 Konfiguration des Ablageordners
der OCT Service User muss berechtigt sein auf den Ordner zugreifen zu können
im Hauptordner https://help.saxess-software.de/sx-cpce-portal/Working-version/datev-upload
ggf. “Mandantenliste.csv” manuell erstellen (überflüssig, aber ohne diese Datei kennt man Beraternummer / Mandantennummer nicht)
- CODE
Beraternr;Mandantennr;Jahr;Mandantenname; 29098;55003;20200101;Musterholz GmbH; Datei “Beraternr_Mandantennr_Mandantendaten_Jahr.csv muss pro Jahr vorhanden sein - Jahr steht hier für den YYYYMMTT String !
- CODE
Unternehmensname kurz»Unternehmensname»Standardkontenrahmen»Länge Sachkonten»WJ-Beginn»WJ-Ende "ABC GmbH"»"ABC GmbH"»"03"»4»01.01.2022»31.12.2022
Unterordner mit Namen “Beraternr_Mandantennr_MMTT_SKR_KtoLänge” erstellen, zB. 29098_55003_0101_03_4
Kontenbeschriftungen_YYYYMMTT.csv
Kontobuchungen_YYYYMMTT.csv
Kostenstellen_traeger_YYYYMMTT.csv
3.2.2 Konfiguration der Prozesspipelines
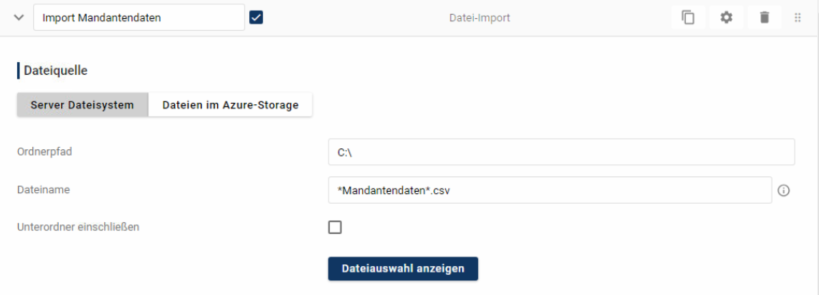
(Hinweis: unter Umständen kann es notwendig sein den kompletten unc-Pfad anzugeben)
Step 1: Import Mandantendaten konfigurieren:
Ordnerpfad und Dateiname (wie angegeben) eingeben
“Verbindung testen” und per “Dateiauswahl anzeigen” prüfen, ob Dateien gefunden werden
Step speichern und aktivieren
Pipeline einmal durchlaufen lassen
Step 2-4:
Import Kontenbeschriftungen, Import Kontobuchungen und Import Kostenstellen_traeger
gleiches Vorgehen wie bei Step 1
Testlauf: die Pipeline muss erfolgreich durchlaufen und die Dateien der Dateien müssen danach in den Tabellen integration.tDATEVAZURE_* stehen
Step SQL Konnektor: aktivieren und Mandanten auswählen
Testlauf: die Pipeline muss erfolgreich durchlaufen und die Daten müssen in den integration.tFIN_ * und global.t* Tabellen stehen
Step Datenbereitstellung aktivieren oder eigenen Datenbereitstellungsprozess implementieren
Testlauf: die Daten müssen danach in den result.t* Tabellen stehen
Fertig, Weiterverarbeitung der Daten je nach Zielsystem
3.3 Anbindung der KOST.mdb
in diesem Modul nicht möglich!!
4. Anpassungsoptionen
Im Konnektor die Schreibweise des Strings “ChartsOfAccountsID” anpassen und ein “SKR” davor setzen.