3.3.11. Step: Excel/CSV
Die “Excel”-/”CSV”-Steps importieren XLS-/CSV-Dateien aus einem lokalen Verzeichnis oder vom Azure Storage in die OCT-Datenbank. Dies dient beispielsweise dazu, wenn Exporte aus Vorsystemen in OCT verarbeitet werden sollen. Beide Steptypen für XLS und CSV verwenden die gleiche Maske.
Dafür müssen passende Zieltabellen (pro CSV Dateiname) in der OCT Datenbank vorhanden sein. Diese müssen folgende Voraussetzungen erfüllen:
sie sind benannt integration.t[CSVFilename].
sie besitzen optional eine erste Spalte “RowKey”, welche nicht in den CSV Dateien als Spaltenname vorkommt.
sie besitzen optional eine zweite (erste falls RowKey nicht vorhanden) Spalte für den Tabellensuffix.
sie besitzen optional eine dritte (zweite falls kein RowKey, erste falls kein Suffix) für eine statische Spalte.
sie besitzen alle Spalten der CSV Datei mit passendem Datentyp.
1. Lokales Dateisystem
Diese Einstellung funktioniert nur bei einer Installation “on premises”. Wenn als Quelle ein lokales Verzeichnis ausgewählt werden soll, muss die Option “Lokales Dateisystem” ausgewählt und der Pfad in das Eingabefeld “Ordnerpfad” eingetragen werden.
Zu beachten ist dabei:
Der Pfad muss existieren.
Alle Dateien aus dem Pfad werden importiert, wenn nur ein Teil importiert werden soll, muss ein Unterordner ausgewählt werden.
Der Nutzer “OCTService” muss Leserechte auf dem Ordner und den enthaltenen Dateien haben.
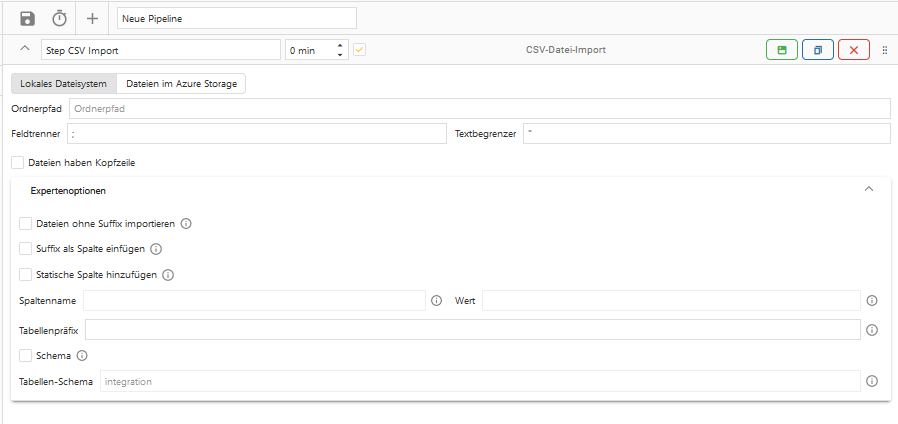
1.1. Allgemeine Optionen
Ordnerpfad
Hier wird der Ordner angegeben, in welchem die zu verarbeiteten Excel-/CSV-Dateien enthalten sind.
Der OCT-Dienst muss lesenden Zugriff auf die angegebenen Excel-/CSV-Dateien besitzen. Es wird empfohlen die Datei im Datenpfad von OCT zu hinterlegen (Standard: "C:\ProgramData\Saxess Sofware\<Dienstname>").
Feldtrenner
Der Feldtrenner beschreibt das Zeichen, welches in der Datei die einzelnen Spalten trennt. Bei CSV-Dateien ist das standardmäßig ein Semikolon.
Textbegrenzer
Der Textbegrenzer ist ein Zeichen, welches Textspalten umgibt, um Anfang und Ende der Spalte zu markieren.
Außerdem kann das Feld hierdurch auch das Feldtrennerzeichen enthalten.
Standardmäßig sind hier Anführungszeichen vorausgewählt.
Wenn die CSV-Dateien keine Textbegrenzer enthalten, hat dies keine negativen Folgen solange sich das entsprechende Zeichen nicht am Anfang oder Ende einer Spalte befindet.
Wenn kein Textbegrenzer angegeben ist, diese sich aber in der CSV-Datei befinden, werden sie beim Import in die Datenbank nicht entfernt.
Dateien haben Kopfzeile
Diese Option gibt an, ob die Dateien eine Kopfzeile haben, welche nicht in die Tabelle importiert werden soll.
1.2. Expertenoptionen
Dateien ohne Suffix importieren
Oftmals enthalten CSV-Dateien ein Suffix am Dateinamen, der das Datum o.ä. markiert.
Wenn mehrere ähnliche Dateien in eine Tabelle importiert werden sollen, kann dieses Suffix (Teil des Dateinamens nach dem letzten Unterstrich) beim Tabellennamen ignoriert werden.
So werden z.B. die Dateien “Testdaten_2018.csv” und “Testdaten_2019.csv” in die Tabelle “integration.tTestdaten” importiert.
Suffix als Spalte einfügen
Diese Option fügt das Suffix (Teil des Dateinamens nach dem letzten Unterstrich) in die erste Spalte der Tabelle ein -die zweite Spalte, wenn eine RowKey-Spalte vorhanden ist.
Dadurch kann die Herkunft der Daten nach Datei rekonstruiert werden.
Statische Spalte hinzufügen
Spaltenname
Entspricht dem Namen der statischen Spalte.
Wert
Ist der Wert für Datensätze in der statischen Spalte.
Tabellenpräfix
Um Dateien mit gleichem Dateinamen je nach Herkunft in unterschiedliche Tabellen schreiben zu können, kann hier ein Präfix für den Tabellennamen angegeben werden.
Dadurch ergibt sich z.B. aus der Datei “Testdaten.csv” und dem Präfix “Präfix_” folgender Tabellenname: “integration.tPräfix_Testdaten”.
Schema
Die Auswahl der Checkbox “Schema” ändert das Schema der Zieltabelle.
Tabellen-Schema
Standardmäßig ist das Schema “integration” ausgewählt.
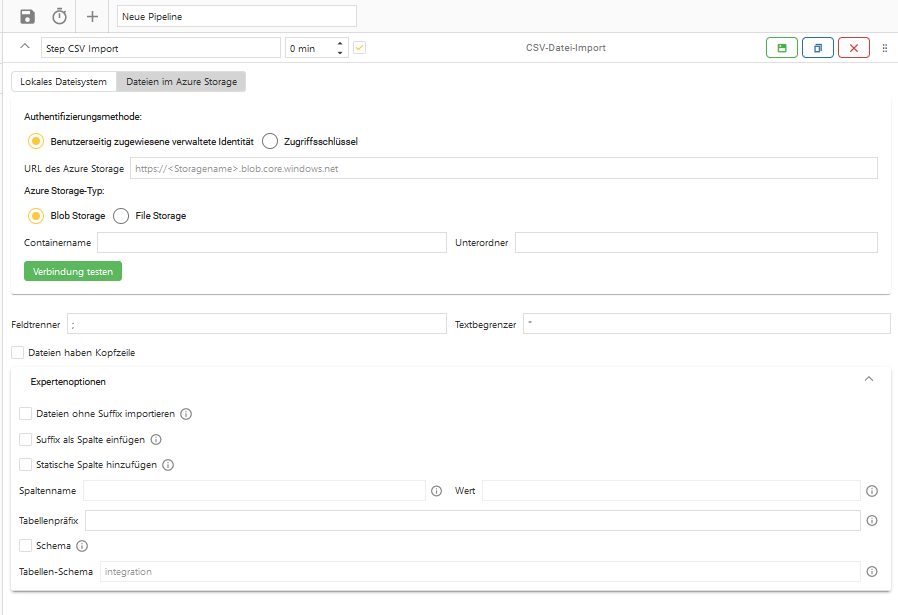
2. Dateien im Azure Storage
Um Dateien aus dem Azure Storage zu importieren, muss die Option “Dateien im Azure Storage” ausgewählt werden. Anschließend hat der Nutzer die Wahl zwischen dem Azure Blob Storage und dem Azure File Storage.
Wenn der Azure Blob Storage ausgewählt wurde, gibt es außerdem die Authentifizierungsarten per Zugriffsschlüssel und per Benutzerseitig zugewiesener verwalteter Identität.
Die Einbindung von Leerzeichen im Pfad erfolgt über Anführungsstriche.
Ferner muss immer der komplette Pfad angegeben werden.
Der Service-Benutzer benötigt Zugriff auf den ausgewählten Ordner/Pfad.
2.1. Authentifizierungsmethode
(a) Benutzerseitig zugewiesene verwaltete Identität
Die Authentifizierung per “Benutzerseitig zugewiesener verwalteter Identität” funktioniert nur, wenn auf den Azure Storage über eine Azure-Instanz von OCT zugegriffen wird - sie erfordert einige Einstellungen in der Azure Subscription.
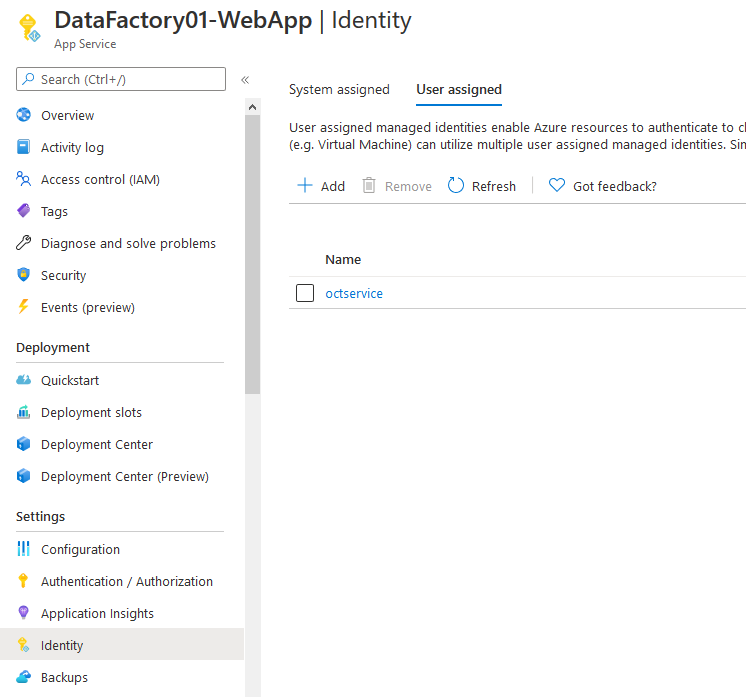
Zunächst muss eine User-assigned managed identity für die Ressourcengruppe, in welcher OCT liegt, angelegt werden.
Anschließend muss diese Managed Identity unter dem Menüpunkt “Identity” zur Webapp hinzugefügt werden sowie zu den einzelnen Deployment Slots:
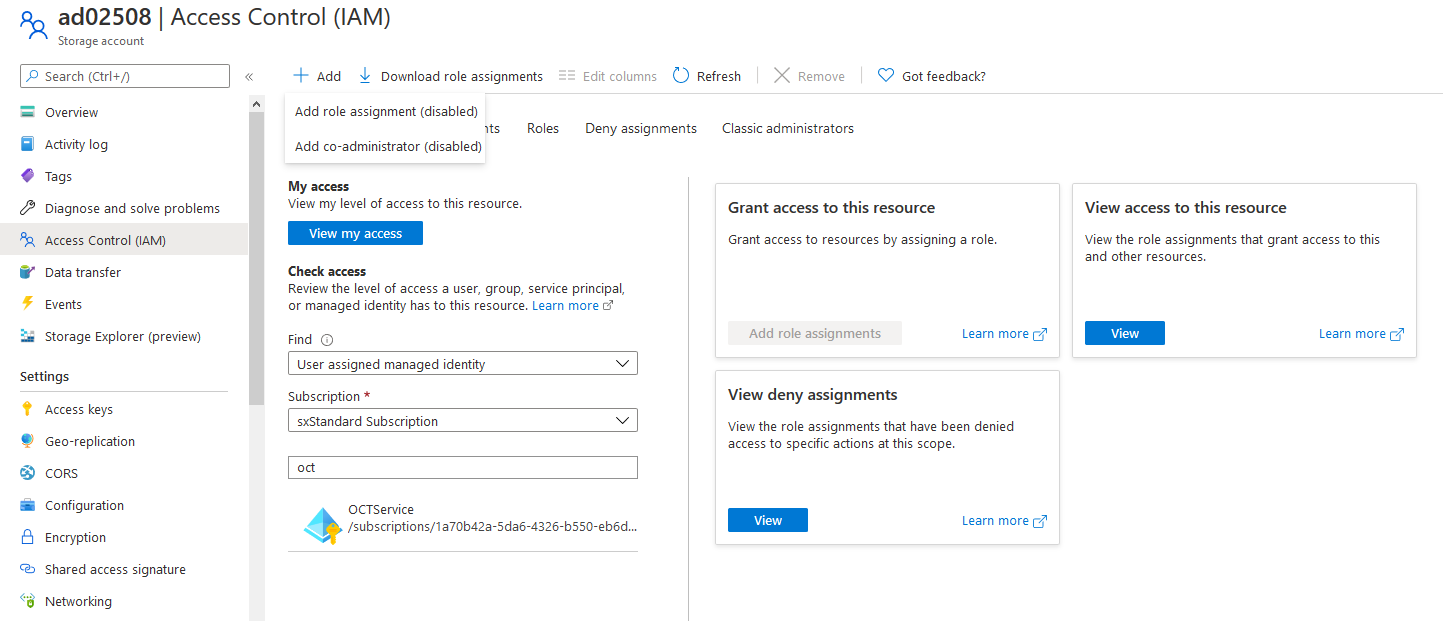
Jetzt muss die Managed Identity auf dem Azure Storage berechtigt werden.
Dafür muss unter dem Menüpunkt “Access Control (IAM)” die Managed Identity eine Rolle zugewiesen bekommen.
Drücken Sie den Button “Add” und wählen Sie “Add role assignment”. Anschließend erfolgt die Auswahl der Managed Identity und eine der Rollen “Storage Blob Data Contributor”, “Storage Blob Data Owner” und “Storage Blob Data Reader”:
Im nächsten Schritt muss noch eine Umgebungsvariable für den Deployment Slot des Azure App Services von OCT erstellt werden. Diese heißt “AZURE_CLIENT_ID” und enthält die ClientID der Managed Identity:
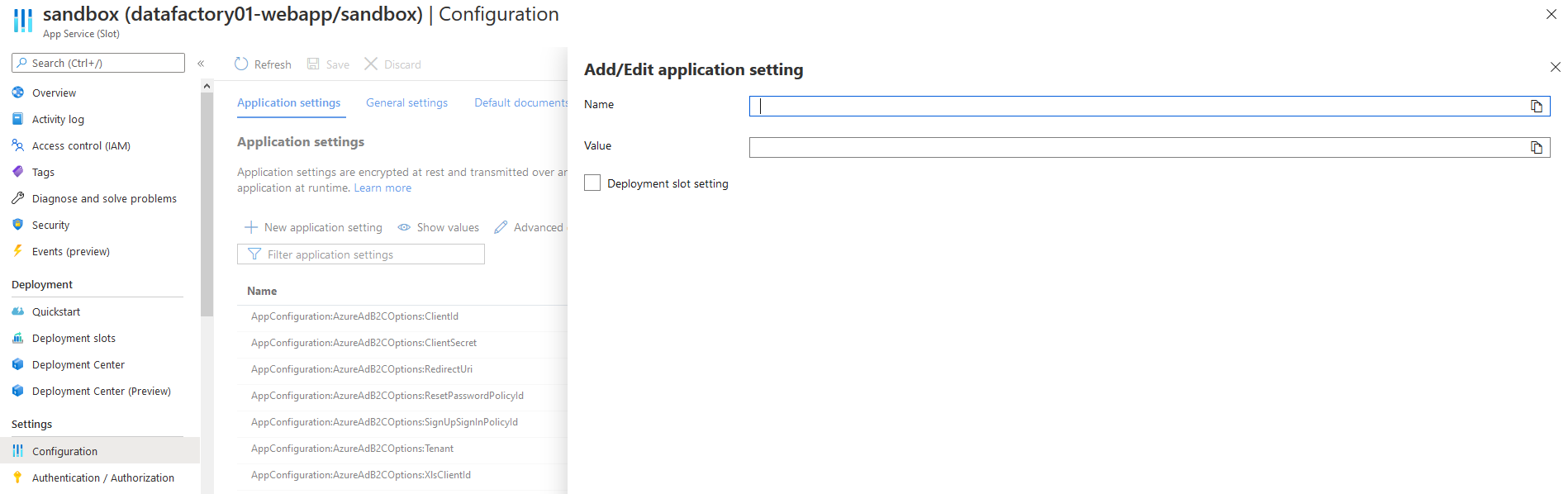
In OCT muss zuletzt die URL “https://<Name des Azure Storage>.blob.core.windows.net” im Feld “URL des Azure Storage” eingetragen werden.
(b) Zugriffsschlüssel
Die Authentifizierung per Zugriffsschlüssel wird direkt vom Azure Storage zur Verfügung gestellt. Diesen findet man im Bereich des Azure Storage-Kontos unter dem Menüpunkt “Zugriffsschlüssel” bzw. “Access Keys”:
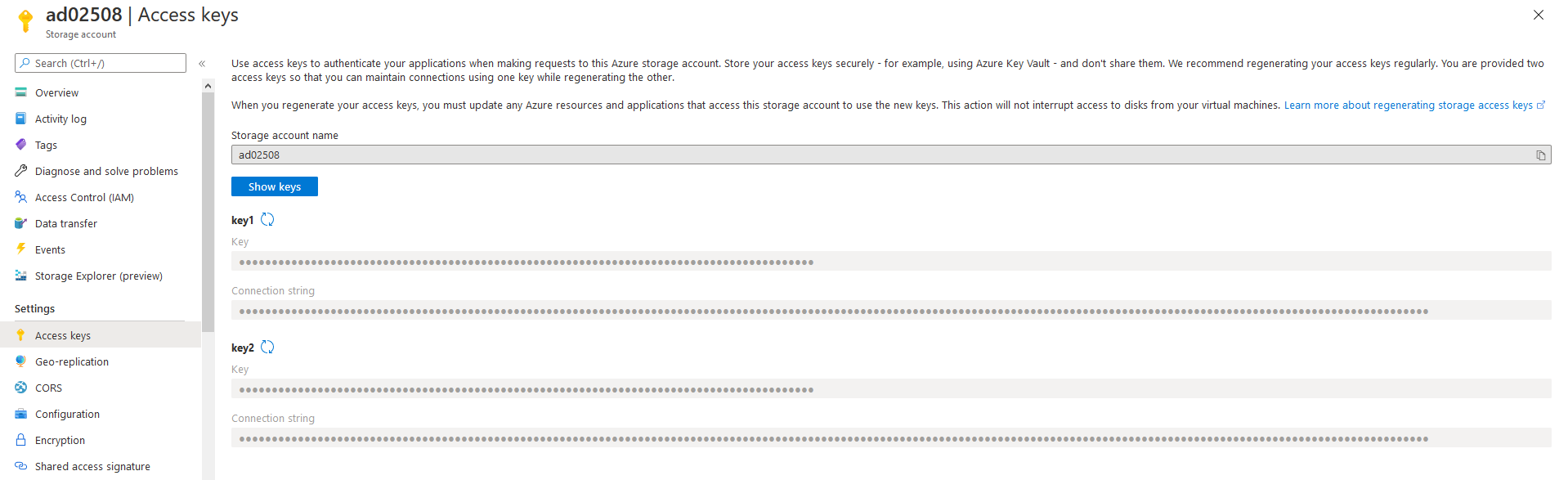
Die Schlüssel müssen über die Funktionalität “Show Keys” angezeigt werden.
Anschließend kopieren Sie den Connection-String des ersten Schlüssels in das Feld “Azure Storage-Zugangsschlüssel”.
2.2. Azure Storage-Typ
(a) Blob Storage
Containername
Ein Container organisiert einen Satz von Blobs, ähnlich wie ein Verzeichnis in einem Dateisystem.
Ein Speicherkonto kann eine unbegrenzte Anzahl von Containern enthalten, weshalb der Name des gewünschten Containers angegeben werden muss.
Unterordner
Blobs können in Ordner oder Unterordner strukturiert sein.
Der gewünschte Unterordner muss angegeben werden.
Verbindung testen
Testet die erfolgreiche Verbindung zum Blob Storage.
(b) File Storage
Sharename
Für File Storages muss stattdessen der Sharename angegeben werden.
Unterordner
Auch hier muss der spezifische Unterordner angegeben sein.
Verbindung testen
Testet die erfolgreiche Verbindung zum File Storage.
2.3. Allgemeine Optionen
Feldtrenner
Der Feldtrenner beschreibt das Zeichen, welches in der Datei die einzelnen Spalten trennt. Bei CSV-Dateien ist das standardmäßig ein Semikolon.
Textbegrenzer
Der Textbegrenzer ist ein Zeichen, welches Textspalten umgibt, um Anfang und Ende der Spalte zu markieren.
Außerdem kann das Feld hierdurch auch das Feldtrennerzeichen enthalten.
Standardmäßig sind hier Anführungszeichen vorausgewählt.
Wenn die CSV-Dateien keine Textbegrenzer enthalten, hat dies keine negativen Folgen solange sich das entsprechende Zeichen nicht am Anfang oder Ende einer Spalte befindet.
Wenn kein Textbegrenzer angegeben ist, diese sich aber in der CSV-Datei befinden, werden sie beim Import in die Datenbank nicht entfernt.
Dateien haben Kopfzeile
Diese Option gibt an, ob die Dateien eine Kopfzeile haben, welche nicht in die Tabelle importiert werden soll.
2.4. Expertenoptionen
Dateien ohne Suffix importieren
Oftmals enthalten CSV-Dateien ein Suffix am Dateinamen, der das Datum o.ä. markiert.
Wenn mehrere ähnliche Dateien in eine Tabelle importiert werden sollen, kann dieses Suffix (Teil des Dateinamens nach dem letzten Unterstrich) beim Tabellennamen ignoriert werden.
So werden z.B. die Dateien “Testdaten_2018.csv” und “Testdaten_2019.csv” in die Tabelle “integration.tTestdaten” importiert.
Suffix als Spalte einfügen
Diese Option fügt das Suffix (Teil des Dateinamens nach dem letzten Unterstrich) in die erste Spalte der Tabelle ein -die zweite Spalte, wenn eine RowKey-Spalte vorhanden ist.
Dadurch kann die Herkunft der Daten nach Datei rekonstruiert werden.
Statische Spalte hinzufügen
Spaltenname
Entspricht dem Namen der statischen Spalte.
Wert
Ist der Wert für Datensätze in der statischen Spalte.
Tabellenpräfix
Um Dateien mit gleichem Dateinamen je nach Herkunft in unterschiedliche Tabellen schreiben zu können, kann hier ein Präfix für den Tabellennamen angegeben werden.
Dadurch ergibt sich z.B. aus der Datei “Testdaten.csv” und dem Präfix “Präfix_” folgender Tabellenname: “integration.tPräfix_Testdaten”.
Schema
Die Auswahl der Checkbox “Schema” ändert das Schema der Zieltabelle.
Tabellen-Schema
Standardmäßig ist das Schema “integration” ausgewählt.