OCT Gateway Personio
Klassifikation
Merkmal | Klassifikation |
Steuerungsstruktur | Auswahl der abzurufenden Tabellen aus Personio über Eintragung der Tabellennamen in eine Liste in der config.json Datei Eingrenzung des Datenabrufs durch Definition von Start- und Enddatum in der config.json Datei |
Quelldatentyp | API |
Validierungsoberfläche | Tabellenstatistik |
Zuletzt getestet mit OCT Version | 5.11.21 |
Programmierpattern | Loop over Tables |
Tabellengruppe | staging.tPERSONIO_* |
Öffentlicher Testdatenbestand | keiner bekannt |
Deploymentweg | manuell |
Inhalte der API | Nachzulesen unter https://developer.personio.de/reference/ |
Bereitstellungvarianten
Service on Demand | Preis | Bemerkungen |
|---|---|---|
Einmaliger Abzug als CSV Dateien | 390 EUR | Wir lesen einmalig alle Personio Daten aus und stellen Ihnen diese als ein Set an CSV Dateien zum Download bereit |
Täglicher Abzug als CSV Dateien | 70 EUR pro Monat | Wir lesen täglich alle relevanten Daten aus und stellen Ihnen diese als ein Set von CSV Dateien bereit. Sie können die Dateien automatisiert in Ihre Umgebung übertragen oder das Verzeichnis als Netzlaufwerk einbinden |
Täglicher Abzug als Microsoft SQL Server Datenbank | 120 EUR pro Monat | Wir lesen täglich alle relevanten Daten aus und stellen Ihnen diese als Microsoft SQL Datenbank bereit. Sie erhalten direkten Zugriff auf diese Datenbank und können die Daten per SQL abrufen und weiterverarbeiten |
Lizenzerwerb | ||
OCT Basislizenz zum Betrieb auf einem eigenen Server | Sofern Sie noch keine OCT Basislizenz besitzen, benötigen Sie die Basislizenz zur Ausführung von OCT Paketen. Diese Lizenz ist nicht nur für das Personio Gateway geeignet, sondern auch für beliebige weitere OCT Lösungen. | |
Personio Paket Kaufversion | Personio Paket in der Kaufvariante. | |
Personio Paket Mietversion | Personio Paket in der Mietvariante mit monatlicher Kündigungsmöglichkeit. |
Funktionalität
Das Gateway spiegelt die ausgewählten Tabellenstrukturen und Daten 1:1 aus der Personio API in die staging Schicht einer OCT Datenbank
die Personio API liefert viele JSON-Objekte, diese werden vom Gateway nicht weiter aufgelöst, sondern 1:1 in die Staging Tabellen geschrieben, Beispiel: Spalte “amount” mit Inhalt: {'currency': ‘EUR’, ‘value’: 0.0}
Die OCT Datenbank stellt eine Validierungsoberfläche für diese Daten bereit
Voraussetzungen
Personio API
Einrichtung der API Zugangsdaten in Personio: https://developer.personio.de/docs/getting-started-with-the-personio-api (Anleitung auf personio.de)
Client-ID, Client-Secret mit den passenden Zugriffsrechten auf die benötigten API-Endpunkte/Tabellen aus Schritt 1
OCT
OCT Applikation 5.11 oder höher - je nach Einrichtungsvariante lokal oder in der Azure Cloud
OCT Datenbank
eine OCT Datenbank als Zieldatenbank muss on-prem oder in einer Cloudumgebung erreichbar sein
Technische Einrichtung
Einrichtung des Gateways mit OCT in der Saxess-Cloud
Voraussetzungen:
Azure Storage Account mit Kontoname und Access Key
in config.json die Zugangsdaten (api_client_id, api_client_secret) für die API, abzurufende Tabellen (in Liste “sql_Tabellen”), Start- und Enddatum und die Zugangsdaten für die Zieldatenbankdaten einfügen
eine Dateifreigabe auf Azure Storage mit dem Namen “python” erstellen, den Inhalt des Ordners Gateway_PersonioAPI in die Dateifreigabe kopieren
Ablaufplan:
Einen Storage Account vom Typ FileStorage als Datenquelle anlegen
1.1 Im Azure Storage Account eine Dateifreigabe “python” (Name ist Konvention) mit einem Ordner “scripts” (Name ist verpflichtend) anlegen
1.2 Den Deployment Ordner “Gateway_PersonioAPI ” aus dem Bitbucket Repo herunterladen und den Inhalt in den Ordner “scripts” kopieren
1.3 falls vorher noch nicht erledigt, im Ordner “config” in der Datei “config.json” die Zugangsdaten (api_client_id, api_client_secret) für die API, abzurufende Tabellen (in Liste “sql_Tabellen”) und die Zieldatenbankdaten einfügen
Datenbankobjekte durch Ausführen des Scripts “SETUP_STAGING_Personio.sql” in die OCT-Datenbank einspielen
in der OCT-Oberfläche unter Datenquellen den Azure Storage Account per AccessKey / Variante FileStorage als Quellsystem hinzufügen
in der OCT-Oberfläche die Pipeline “STAGPER - Datenextraktion Personio” öffnen
4.1 (falls vorhanden) Step: “Powershell - Datenextraktion Personio” löschen oder deaktivieren
4.2 im Step: “Container - Datenextraktion Personio” die Azure Datenquelle einstellen, unter Startbefehl config anpassen falls der Name der config.json angepasst wurde
4.3 Pipeline ausführen
Datenvalidierung in OCT über die Factory Validierung, Productline Staging Personio
im Tab START der Personio Validierung den Link zur Tabellenübersicht anpassen
Einrichtung des Gateway mit OCT on Premises
Ablaufplan:
Den Deployment Ordner “Gateway_PersonioAPI” aus dem Bitbucket Repo herunterladen, und nach C:\ProgramData\Saxess Software\ kopieren
benötigte Pythonpakete installieren
3.1 ein Terminal als Admin starten
3.2 zum Gateway_PersonioAPI Ordner wechseln mit “cd ../../ProgramData/Saxess Software/Gateway_PersonioAPI”
3.3 mit folgendem Befehl Pakete installieren: “python -m pip install -r requirements.txt”
Datenbankobjekte durch Ausführen des Scripts “SETUP_STAGING_Personio.sql” aus dem Ordner “setup” im Gateway_PersonioAPI Ordner in die OCT-Datenbank einspielen.
Die Tabellen werden nach Ausführung des Pythonskript angelegt.in der Datei “config.json” im Ordner “config” die DatenquellenID, Zugangsdaten für die Personio-API (api_client_id, api_client_secret), abzurufende Tabellen (in die Liste “sql_Tabellen”) und die Zieldatenbankdaten einfügen
(optional): testweise Direktausführung
Python Script main.py im Terminal ausführen (python main.py --config=config.json), alternativ test_datenabruf.bat im “Gateway_PersonioAPI” Ordner starten
Pipeline STAGPER-Datenextraktion Personio einrichten:
7.1 Step: “Container - Datenextraktion Personio” löschen oder deaktivieren
7.2 Pipeline Schedule einstellen falls benötigt
7.3 Pipelineausführung testen
Datenvalidierung in OCT über die Factory Validierung, Productline Staging Personio
8.1 im Tab START der Personio Validierung den Link zur Tabellenübersicht anpassen
Konfiguration der config.json Datei
Auswahl der abzurufenden Tabellen über Eintragung der API - Endpunkte
folgende Personio API V1 Endpunkte können unter “sql_tabellen” eingetragen werden:
"v1/company/employees"
, "v1/company/employees/attributes"
, "v1/company/attendances/projects"
, "v1/company/attendances"
, "v1/company/time-offs"
, "v1/company/time-off-types"
, "v1/company/absence-periods"
, "v1/company/attendances/projects"
, "v1/company/document-categories"
, "v1/company/custom-reports/reports"
folgende Personio API v2 Endpunkte können unter “sql_tabellen” eingetragen werden:
"v2/persons"
, "v2/persons/{person_id}/employments"
, "v2/absence-periods"
, "v2/absence-periods"
, "v2/absence-types"
, "v2/attendance-periods"
, "v2/compensations"
, "v2/compensations/types"
, "v2/legal-entities"
, "v2/cost-centers"
Das Feld “api_url” bitte nicht ändern, api_v1_batch_size hat ein Maximum von 200 und sollte nicht geändert werden.
Zeitliche Eingrenzung des Datenabrufs
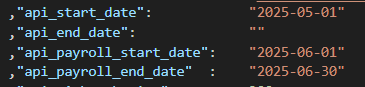
Der Datenabruf kann mit “api_start_date” und “api_end_date” eingegrenzt werden, die Datumsangabe erfolgt im Format yyyy-mm-dd. Dies gilt für alle Endpunkte außer für v2/compensations, falls dieser abgerufen werden soll, bitte das Datum bei “api_payroll_start_date” und “api_payroll_end_date”, auch im yyyy-mm-dd Format einfügen, und darauf achten dass die Differenz zwischen beiden Daten gleich oder kleiner einem Monat entspricht. Wenn beide “api_payroll_date” Felder leer sind (“ “), werden die Daten des aktuellen Monats abgerufen. Falls alle verfügbaren Daten abgerufen werden sollen, die Felder für die Datenangaben bitte freilassen (“ “).
Beispielkonfiguration die alle Daten seit dem 1. Mai 2025 abruft, sowie die Compensations die im Juni 2025 aktiv waren:
Output
"csv_out_aktiv" : 1
"db_output_aktiv": 1
Entscheidet ob die abgerufenen Daten in die Zieldatenbank geschrieben oder als CSV Datei auf der Festplatte oder im Azure File Share abgespeichert werden sollen. 1 = aktiviert, 0 = deaktivert
Beide Optionen können gleichzeitig aktiv sein.
Bei Ausführung des Gateway-Skripts im Container-Step den “ziel_ordner” im Abschnitt “Dateisystem” freilassen, da das Skript dann die Daten im File Share ablegt.