3.7. Modellierungsregeln für Module und Konnektoren
OCT verwendet die Begriffe “Modul” und “Konnektor” um vorgefertige Inhalte für die OCT Datenbank zu verwalten. Die Gesamtheit von Modulen und Konntektoren wird als “OCT Content” bezeichnet
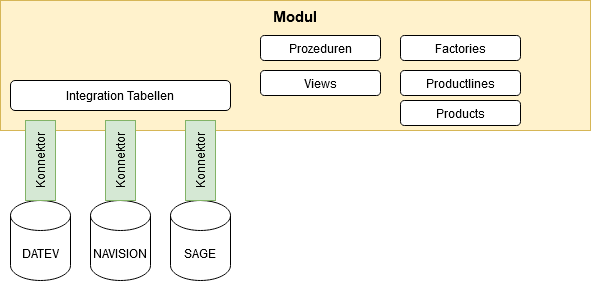
Modul
Das Modul ist eine Strukturvorlage, welche technische Inhalte der Datenbanken und logische OCT Objekte umfasst
technische Inhalte
Tabellen
Prozeduren
Funktionen
Views
logische Inhalte
Factories
Productlines
Products (mit und ohne Daten)
Listen
Formate
Datenquellen
Pipelines
Tabs
Der Inhalt und Umfang eines Moduls kann sehr verschieden sein, üblich sind
ein Integrationsmodul - ein Modul um Daten aus einem Vorsystem in ein vorgefertiges Speicherschema zu extrahieren, es umfasst
Tabellen im integration Schema
Tabellen im result Schema
Prozeduren im agent Schema
Pipelines
ein Add ON Modul - kleines Ergänzungsmodul, welches ein paar zusätzliche Sichten, Prozeduren etc. bereitstellt
ein Validierungsmodul - Modul um die Daten eines Integrationsmoduls zu validieren
eine Factory / Productline im ZT Bereich der Datenerfassung
Prozeduren zum Datenabruf
Tabs zur Anzeige der Prozedurwerte als Pivottabelle etc.
ein Planungsmodul - die umfangreichste Form eines Moduls, kann das gesamte Set an technischen und logischen Inhalten umfassen
Kann man mehrere Module kombinieren ?
Es gibt Module welche sich mit anderen Modulen (in Grenzen) vertragen und es gibt Alpha Tiere die keine anderen Alpha Tiere neben sich tolerieren. Sie können davon ausgehen
Integrationsmodule, AddONs und Validierungsmodule kann man gleichzeitig in ein Datenbank einspielen
Planungsmodule sind immer Alphas - sie tolerieren höchstens noch ein kleines AddOn neben sich, auf keine Fall aber ein anders Planungsmodul
Konnektor
Ein Set an SQL Abfragen mit Platzhalter Parametern, welches Tabellen im Integration Schema eines Moduls mit Daten aus einem Vorsytem füllt. Der Konnektor existiert, da ein Modul (bspw. das Modul FIN “Finanzbuchhaltung”) aus ganz verschiedenen Finanzbuchhaltungssystemen gefüllt werden kann. Das Modul ist somit in diesem Fall immer identisch, es gibt aber Konnektoren für das Modul zu verschiedenen Finanzbuchhaltungssystemen.
Der Konnektor ist somit der “Schuko Stecker” um ein Modul an verschiedenste System anzuschließen. Ein Modul muss aber nicht über “Schuko-Stecker” angeschlossen werden. Das Modul kann sich auch direkt mit einer Quelle per Pipeline verdrahten. Es ist also wie zuhause - alles was schnell und beweglich angeschlossen werden soll (Föhn, Toaster, Wasserkocher) nimmt den Schuko Stecker. Also was viel Leistung braucht und unbeweglich ist (Hauptverteiler, Durchlauferhitzer) wird fest verkabelt.
Merksatz: Ein Konnektor kann nicht ohne Modul arbeiten. Aber ein Modul braucht nur in manchen Fällen einen Konnektor.
Das Modul muss immer vor dem Konnektor geschaffen werden.
Der Konnektor ist eine normale SQL Abfrage (in 99% der Fälle ein SELECT ….FROM, aber das ist nicht zwingend), welches in seiner Definition Platzhalter besitzt. Diese Platzhalter werden zur Laufzeit ausgefüllt, so das die Abfrage passend zur Aufgabe
bestimmt Mandanten extrahiert
bestimmte Jahre extrahiert
Regeln für Integrationsmodule
erstellen sie für jede aus dem Vorsystem abzuholende Tabelle im integration Schema eine Zieltabelle mit den benötigten Spalten
erstellen sie für Dimensionstabellen eine Tabelle im global Schema
erstellen sie Zieltabellen im result Schema - diese sollten ein Starschema bilden um für den Endanwender leicht konsumierbar zu sein
erstellen sie einen View für jede result Tabelle, welcher sich per SELECT INTO in die Zieltabelle materialisieren lässt
verwenden sie Indexierung in den Tabellen nach folgenden Grundregeln → jede Tabelle muss einen Clustered Index besitzen
integration Schema Tabellen erhalten einen einfachen Primärschlüssel (RowKey) als CLUSTERED INDEX
global Schema Tabellen erhalten einfachen Primärschlüssel (RowKey) als CLUSTERED INDEX
result Schema Faktentabellen erhalten einen CLUSTERED COLUMNSTORE INDEX und einen einfachen Primärschlüssel (RowKey) als NONCLUSTERED INDEX
result Schema Dimensionstabellen erhalten einen einfachen Primärschlüssel (RowKey) als NONCLUSTERED INDEX und ggf. einen CLUSTERED INDEX in der Reihenfolge MandantenID, DimensionsID
Azure: ein Columnstore Index ist nur ein größeren Datenbankkonfigurationen enthalten und begrenzt im Speicherplatz - verwenden sie ihn daher nur für die Faktentabellen