Leitfaden für die Erstellung von Staging Schichten (Gateways)
Ein Gateway überwindet Grenzen - es macht einem Benutzer Daten zugänglich, die hinter einer technischen oder benutzerrechtlichen Mauer liegen. Wir überwinden diese Mauer durch technisches Wissen oder durch unsere Vertrauenstellung als erfahrene Datawarehouseexperten.
Zielstellung
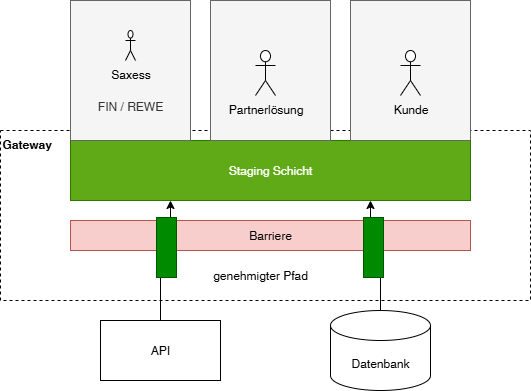
Eine Staging Schicht spiegelt die Daten aus einem Produktivsystem in eine Datenbank zur Weiterverarbeitung. Die Daten werden dabei weitgehend 1:1 gespiegelt. Die Staging Schicht soll breit sein und verschiedenen Folgeprozessen / Modulen eine Datenbasis bieten.
Wann werden Gateways erstellt
falls die Daten der Datenquellen nur über eine technisch anspruchsvolle Technologie ausgelesen werden können (API)
falls der direkte Zugriff auf die Datenquelle für den Endbenutzer
aus technischen Gründen nicht erlaubt ist (Produktivsystem darf nicht durch Auswertungsabfragen belastet werden)
aus rechtlichen Gründen nicht erlaubt ist (in der Datenquelle sind mehrere Mandanten, aber der Benutzer darf nur einen davon sehen)
Fünf Wünsche an Staging Prozesse von Benutzern
Erlaube mir eine einfache und sichere Konfiguration
erstelle eine config Datei, welche der Hauptprozess einliest
alle Konfigurationsparameter für Verbindungen und Passwörter kommen in die config Datei
lass mich den Hauptprozess mit einer ausgewählten config Datei starten
so kann ich den Hauptprozess jederzeit in eine Versionsverwaltung ohne credentials einchecken
Berücksichtige, dass ich vielleicht mehrere Instanzen eines Vorsystems in die Zieldatenbank einlesen möchte
lass mich daher in der config Datei eine DatenquellenID definieren und stelle die Spalte DatenquellenID als führende Spalte vor jede Tabelle
TRUNCATE Tabellen nur mit meiner Zustimmung, normalerweise erfolgt nur ein DELETE für die bei Aktualisierungen
Gib mir ein Inhaltsverzeichnis und eine Auswahlmöglichkeit
zeige mir zunächst den Bestand an Mandanten und Geschäftsjahren, lass mich dort auswählen, welche ich gespiegelt haben möchte
teile umfangreiche Datenbestände in logische Partitionen (Buchhaltung, Warenwirschaft, Vertrieb…) um bestimmte Bestände einzuschließen oder auch nicht
lass mich flexibel entscheiden, welche Mandanten / Geschäftsjahre / Datenbestände ich jeweils aktualisiert haben möchte
rechne damit, dass ich ausgewählte Datenbestände (ein Geschäftsjahr von einem Mandanten) schnell mal außerordentlich aktualisieren möchte
rechne damit, dass meine Wünsche wachsen werden falls ich glücklich bin - ich werde mehr Bestände haben wollen und mehr mit der Datenbasis tun wollen
Gib mir meine Daten in meiner Sprache und in meiner Struktur
kopiere meine Daten 1:1 so wie sie in der Quelle sind - gib mir viele Attribute, welche für mich nützlich sein könnten
ändere keine Namen und gib mir jede Tabelle einzeln mit ihrem originalen Namen, dann kann ich die Daten leicht wiedererkennen und auch in der Herstellerdokumentation dazu nachschlagen
wandle Spalteninhalte nur um, wenn sie dadurch für mich leichter konsumierbar werden
füge mir ggf. Spalten ein, welche mir das joinen der Tabellen erleichtern
Lass mich sehen, ob alles funktioniert
zeige mir ein gut lesbares Log
zeige mir, wie viele Daten im Bestand sind und ob sie aktuell sind
validiere Summen, wo es universtell möglich ist
Desginregeln
Das Python Framework aus dem Repo nutzen.
DataFrame schreiben
soll über geprüfte Methode passieren (ca. 20.000 Zeilen nach Azure / 1.000.000 Zeilen lokal sollten erreicht werden)
soll bei großen Datenmengen Fortschrittsbalken im Log zeigen
soll Durchsatz messen und ins Log schreiben
Daten sollen fortlaufend in die Datenbank geschrieben um den Arbeitsspeicher zu entlasten und in der Datenbank den Fortschritt zu sehen
Ausführbarkeit
das Gateway soll in einer lokalen Umgebung ausführbar sein
Gateways mit Scriptcode müssen in Cloudumgebungen im Container ausführbar sein
Komplexe Typen
komplexe Rückgabewerte innerhalb von Tabellen (JSON Objekte, Arrays etc.) werden im Stagingprozess in der Regel nicht aufgelöst, sondern als String gespeichert, sofern sich dieser über SQL gut auflösen lässt
Logging
Aktion mit Parametern und Zeitstempel
Anzahl gelesener Zeilen / Spalten
Fehler / Warnungen
Errorcounter um zwischenzeitliche Fehler zu zählen und am Ende den Exit Code zu steuern
für die Übergabe noch OCT sollte zwischen den Debuggleveln Error, Warning und Info umgeschalten werden können
Indexierung der Tabellen
noch nicht konzeptioniert
A: kein Index (Heap) - höchste Schreibperformance, aber Aufblähgefahr
B: Spalte RowKey als Clustered Index - vermeidet aufblähen, Index ist aber ansonsten nutzlos
Desigenpattern
Staging Schichten müssen sehr einfach und nach wiederkehrenden Muster geschrieben werden. So viel wie möglich in einer Anbindung soll aus vorgefertigen und geprüften Codebausteinen erstellt sein.
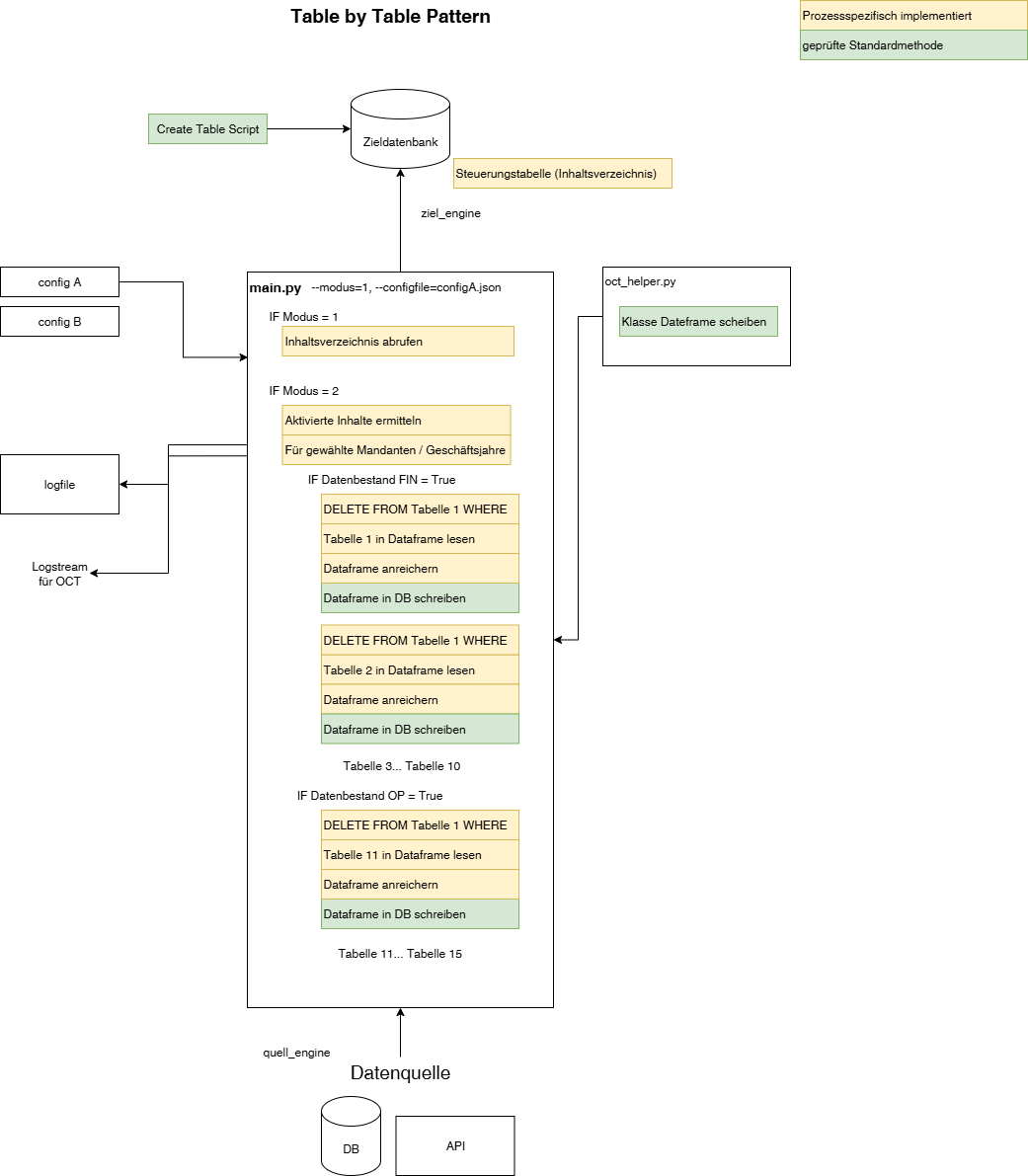
Table by Table Pattern
die äußere Kontrollstruktur definiert zumindest den Mandanten, ggf. auch das Geschäftsjahr
einfacher linearer Ablauf für eine übersichtliche (meist < 20) Anzahl von Tabellen7
die Zieltabellen werden manuell vorab erstellt
der Prozess bearbeitet linear Tabelle für Tabelle
jeder Tabellenabruf ist einzeln definiert
jede Tabelle erfährt eine allgemeine Anreichung (DatenquellenID)
jede Tabelle kann eine individuelle Anreicherung erfahren (Schlüsselspalten)
Vorteile
auf jede Tabelle kann individuell eingegangen werden
Datentypen werden vorab definiert und stehen als Ziel fest
leichte Lesbarkeit
Nachteile
Codewiederholungen
Tabelle müssen manuell angelegt werden
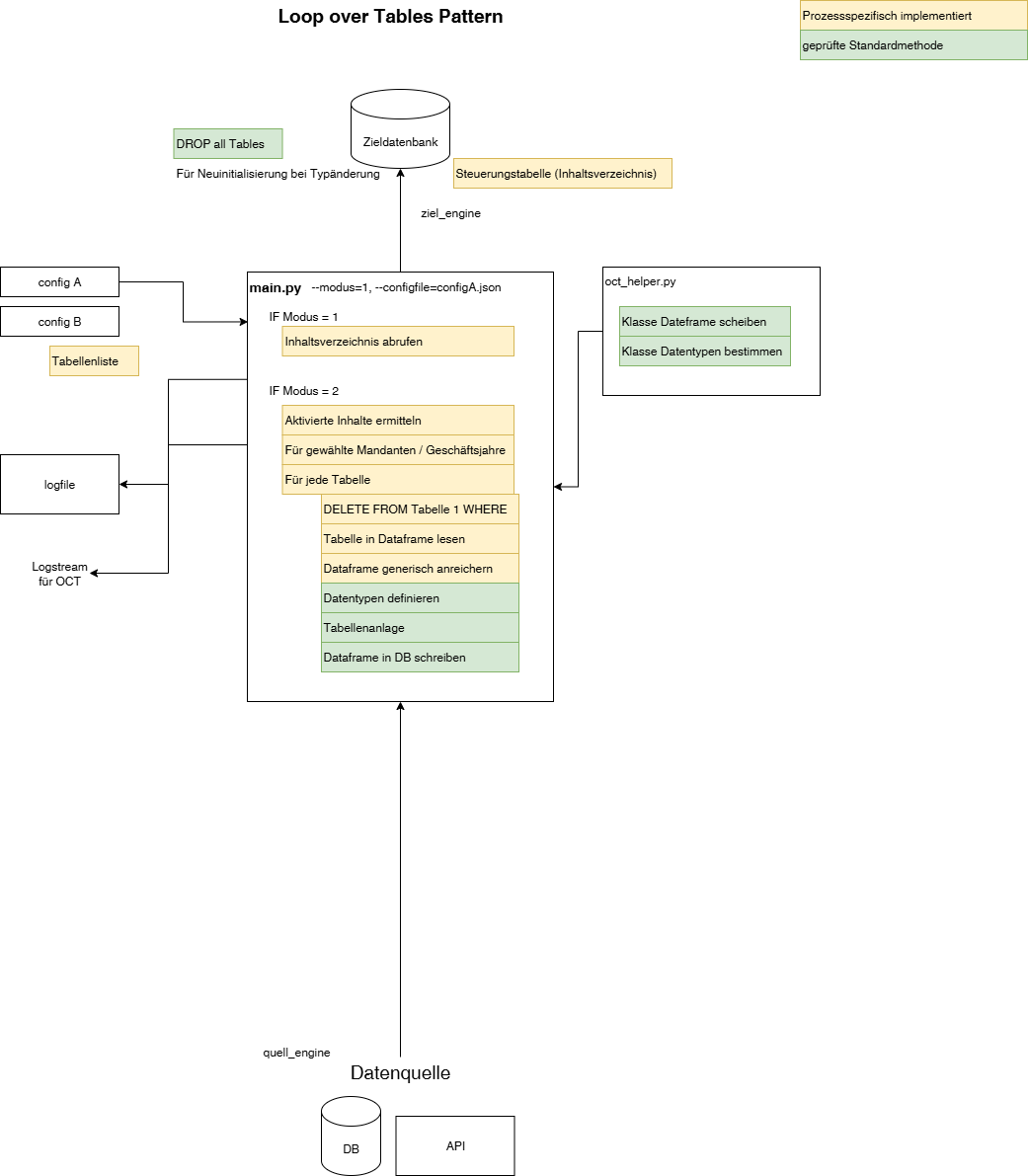
Loop over Table-Array Pattern
generischer Lauf über eine Liste von Tabellen
die Zieltabellen werden vom Prozess erzeugt
Vorteile
wenig Codewiederholungen
sehr leichte Erweiterbarkeit
Nachteile
jede Tabelle wird gleich behandelt, auf Besonderheiten der Tabelle kann schwer eingegangen werden (nur per hartem IF Tabellenname = )
Datentypen werden durch Prozess bestimmt → unsicher, Prozess muss bei jedem Loop die Typkonformität prüfen und bei ggf. Neuerstellung anfordern
Datentyp kann nicht bestimmt werden, falls im ersten Loop eine Spalte nur NULL Werte enthält, Typ muss dann auf String festgelegt werden
Scriptssprache
Die Implementierung sollte in Python erfolgt
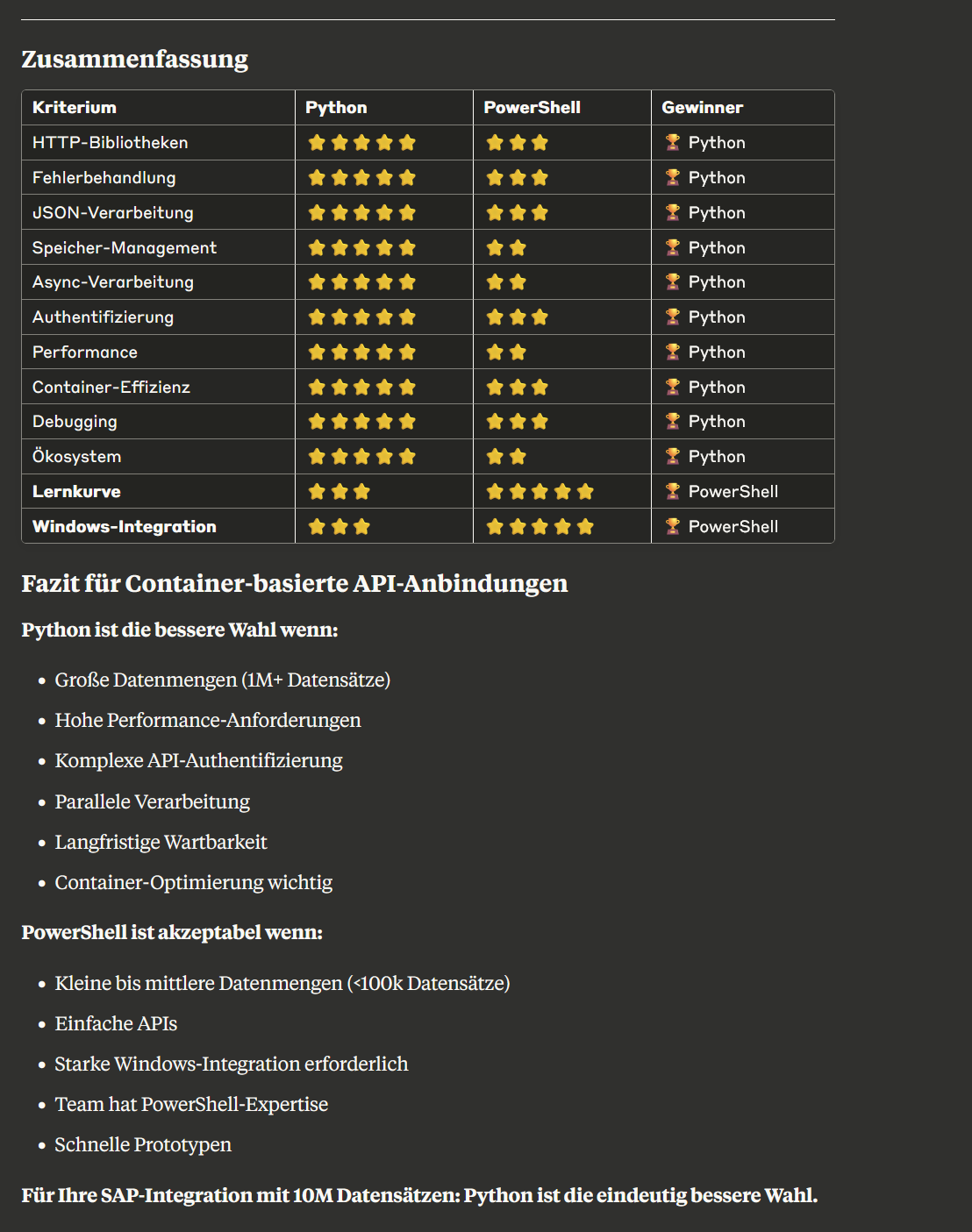
Vergleichsdokument (erstellt mit Claude) : Python vs PowerShell - Web-API Vergleich für Container.pdf
Beispiel für DATEV Connect
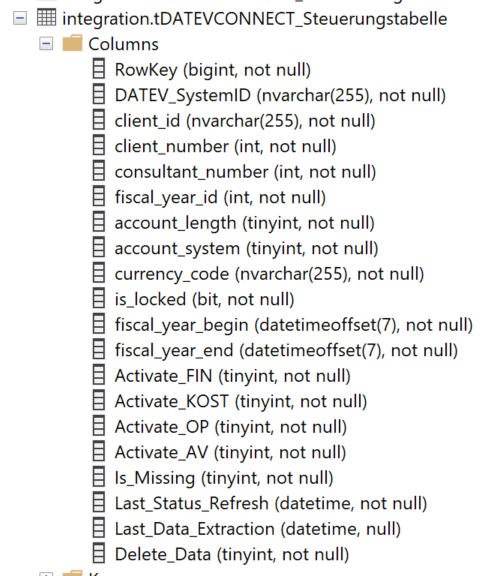
Tabellennamen (hier noch im Schema integration, besser im Schema staging speichern
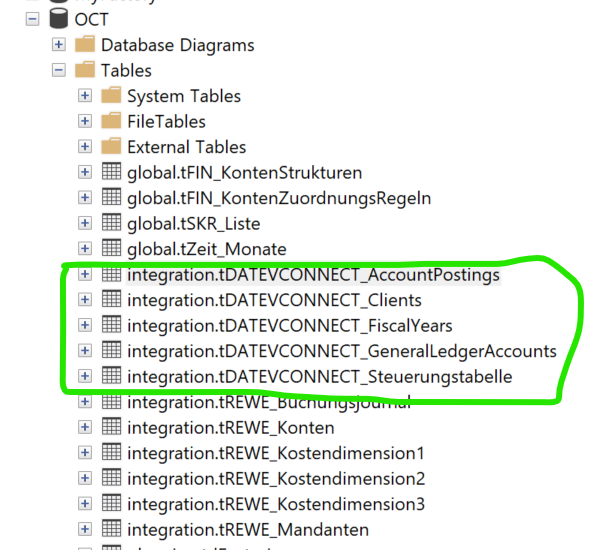
Spalten der Steuerungstabelle