1.1. Tab-Typ: Pivot-Tabelle
Tabs vom Typ “Pivot” stellen Daten mit aggregierbaren Fakten zur Auswertung bereit. Dieser Artikel soll erklären, wie Sie ohne SQL-Kenntnisse eine einfache Pivot-Übersicht Ihrer Produkte (Faktentabellen) bauen können.
Version: Dieser Artikel ist mindestens gültig ab der Applikationsversion 5.5.
Zusätzliche Informationen zum Tab “Pivot-Tabelle” finden Sie im Handbuch der Applikation unter: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle und https://help.saxess-software.de/oct-handbuch/v511/3-3-8-1-tabs-allgemein.
1. Voraussetzungen
Pivot-Tabs benötigen für eine gespeicherte Prozedur eine Datenquelle. Es gibt folgende grundlegende Möglichkeiten:
OCT liefert bei der Installation Standardprozeduren aus, z.B. die “result.spPlanningProfit”.
Eine selbstgeschriebene Prozedur - diese benötigt aber SQL-Kenntnisse und ein SQL Server Management Studio.
Die Daten, welche eine solche Prozedur zeigt, können aus OCT Products oder aus beliebigen berechneten / importieren Datenbeständen kommen.
Ein Tab vom Typ “Pivot” kann auf mehreren Auswertungsebenen verwendet werden:
auf Werkebene
auf Fabrikebene
auf Produktlinienebene
2. Verwendungsanleitung
Der Prozess rund um die Verwendung eines Pivot-Tabs wird…
mit einem einfachen Produkt des Typs “Mietvertrag” aus unserer Demo: https://www.saxess-software.de/loesungen/vertragsmanagement/#1637923776053-f28a538f-d73d und
mit der Standardprozedur “result.spPlanningProfit” erklärt, welche mit jeder OCT-Installation ausgeliefert wird.
2.1. Datenarten
Die zugrundeliegende gespeicherte Prozedur kann beliebige Daten ausgeben:
Alle Felder können als Zeilen / Spalten / Filter einer Pivot-Tabelle verwendet werden.
Nur numerische Werte können als Fakten verwendet werden.
Eine Pivot-Tabelle kann nur aggregieren - daher sollten die Daten von der Prozedur vorzeichengerecht erzeugt werden - z.B. alle Erträge positiv, alle Kosten negativ.
Die folgende Tabelle zeigt einige Standardprozeduren von OCT, die für die Verwendung im Pivot-Tab geeignet sind:
Prozedur | Inhalt | Vorzeichensteuerung | Bemerkung |
|---|---|---|---|
result.spPlanningProfit | Alle numerischen Werte mit GuV-Wirkung (Erkennung über Effekt) | Kosten erscheinen negativ, Erlöse positiv | |
dbo.sx_pf_DATAOUTPUT_NumericValues | Alle numerischen Werte, egal welcher Effekt | keine | |
dbo.sx_pf_DATAOUTPUT_TextValues | Alle Textwerte, egal welcher Effekt | ||
dbo.sx_pf_DATAOUTPUT_Balance | Alle Bilanzwerte (Erkennung über Effekt) | Passiva negativ, Aktiva positiv | |
dbo.sx_pf_DATAOUTPUT_CashValues | Alle zahlungswirksamen Werte (Erkennung über Effekt) | Auszahlungen erscheinen negativ, Einzahlungen positiv | |
result.spEvents | Alle Events mit Bemerkungen | Wertet nur Texte der ValueSeriesIDs E und BEM aus, stellt diese aber nebeneinander da. |
Effekte und die Eigenschaft “Numerisch” können in den Wertreihen der Produktdatentabellen über das Icon
 “Wertreihen bearbeiten” geändert werden: https://help.saxess-software.de/oct-handbuch/v511/3-3-5-produkte#id-(v511)3.3.5.Produkte-3.3.5.3.2.Wertreihenbearbeiten
“Wertreihen bearbeiten” geändert werden: https://help.saxess-software.de/oct-handbuch/v511/3-3-5-produkte#id-(v511)3.3.5.Produkte-3.3.5.3.2.Wertreihenbearbeiten

Bild 1: Anpassung der gewünschten Eigenschaften von Wertreihen am Beispiel des Produktes “Mietvertrag” (OCT Version 5.11)
Die Übersetzung mittels Faktoren erfolgt in der Datenbank über die Tabelle planning.tgValueEffects. Die hier verwendete Beispielprozedur “result.spPlanningProfit”:
importiert z.B. Zahlenwerte mit dem Effekt “Kosten=Auszahlg” und verrechnet diese mit einem Faktor = -1.
importiert z.B. Zahlenwerte mit dem Effekt “Aktivbestand” gar nicht.
Anwender mit Datenbankkenntnis und -zugriff können somit die Liste der Effekte anpassen.
Bild 2 zeigt die Wertreihen und die eingetragenen Werte in unserem Beispielprodukt “Mietvertrag”:
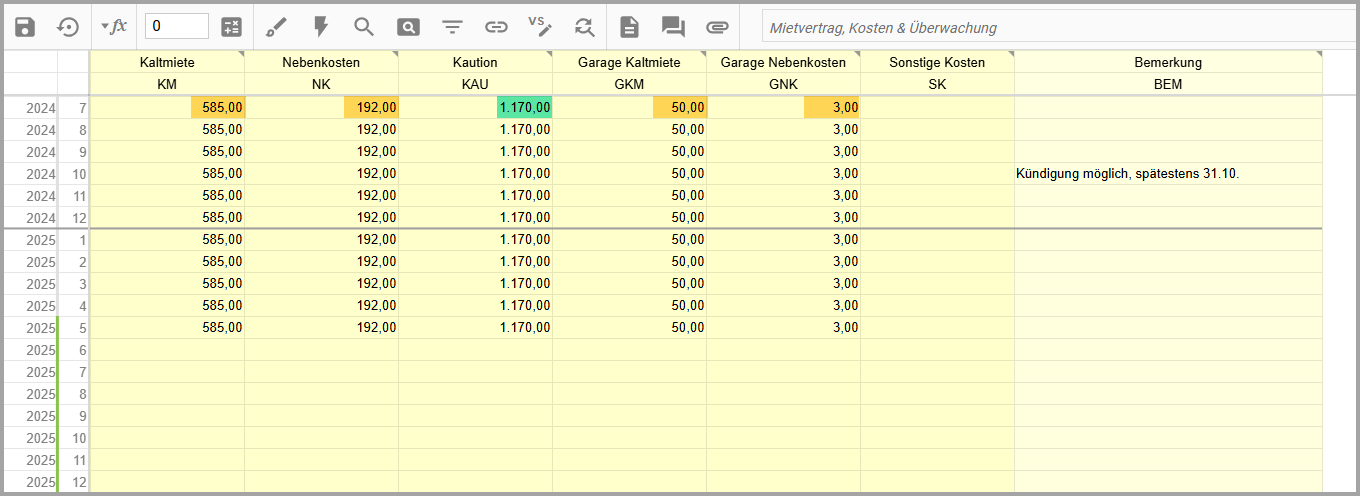
Bild 2: Ansicht der Produktdatentabelle mit den im Bild 1 angepassten Wertreihen (OCT Version 5.11)
Die Summe aller Werte (für 2024/07) in Wertreihen mit dem Effekt “Kosten=Auszahlg” = 585 + 192 + 50 + 3 = 830.
Die Wertreihe Kaution mit dem Effekt “Aktivbestand” hat den Wert = 1170.
2.2. Erstellung eines Pivot-Tabs
Ein Tab vom Typ “Pivot-Tabelle” kann auf den Ebenen “Werk”, “Fabrik” oder “Produktlinie” in der Menüleiste über das Icon
 “Tab hinzufügen” neu erstellt werden.
“Tab hinzufügen” neu erstellt werden.Öffnen Sie den Dialog “Tab hinzufügen” (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.1.Tab%E2%80%9CPivot-Tabelle%E2%80%9Dhinzuf%C3%BCgen) auf der Ebene (Fabrik, Produktlinie,..), auf welcher der Auswertungs-Tab erstellt werden soll.
Der Tab kann über eine gespeicherte Prozedur oder über einen SQL-Befehl erstellt werden. Wählen Sie bei “Gespeicherte Prozedur” die Standardprozedur “result.spPlanningProfit” als Datenquelle.
Der Tab kann über das Icon
 “Optionen” (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.2.1.Optionen-Pivot-Tabelle) angepasst werden.
“Optionen” (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.2.1.Optionen-Pivot-Tabelle) angepasst werden. Die Felder der Pivot-Tabelle können über das Icon
 “Feldliste anzeigen” (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-Icon%E2%80%9CFeldlisteanzeigen%E2%80%9D und https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.3.1.AnsichtderTabelle-Feldauswahl) ausgewählt sowie neue Aggregationsfelder über die Optionen (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.2.1.Optionen-Pivot-Tabelle) erstellt werden.
“Feldliste anzeigen” (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-Icon%E2%80%9CFeldlisteanzeigen%E2%80%9D und https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.3.1.AnsichtderTabelle-Feldauswahl) ausgewählt sowie neue Aggregationsfelder über die Optionen (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.2.1.Optionen-Pivot-Tabelle) erstellt werden.Bild 3 zeigt eine typische Standardauswahl an unserem Beispiel:

Bild 3: Feldauswahl im neu erstellten Tab
Die Reihenfolge der Felder in der Feldauswahl, z.B. in den Zeilenfeldern, zueinander ist entscheidend für das spätere Tab-Layout. Das oberste Feld (FactoryName) ist gleichzeitig die oberste ausklappbare Zeilenebene im Pivot-Layout.
Sind alle Felder (Spalten und Zeilen) in der Pivot-Tabelle ausgeklappt, so ist auch das Produkt “Mietvertrag” in der Auswertung sichtbar.
Wir benötigen dafür mindestens die Produkte (z.B. ProductName), die Jahre/Monate (Year, Month) und die Werte (Value) um einen Vergleich, mit der beispielhaft berechneten Summe aus Bild 2 oben, anstellen zu können.
Vollständig ausgeklappt sieht es am Beispiel unserer Demo wie folgt aus:

Die Summe aller Werte aus Wertreihen mit dem Effekt “Kosten=Auszahlg” sind hier korrekt dargestellt und mit dem Faktor = -1 verrechnet.
Mit einem Linksklick in ein Feld öffnet sich ein Kontextmenü, über welches Sie schnell alle Zeilen / Spalten im Betrieb auf- und einklappen können. Für eine gute Ladeperformance bei großen Datenmengen sollten Sie alles eingeklappt speichern.

2.3. Darstellung von Differenzen
Differenzen sind nicht ganz so einfach darzustellen, da die Pivot Darstellung von Haus aus vor allem auf das Summieren ausgelegt ist.
Es gibt zwei Grundansätze für Differenzen:
Weg A: Positive - Negative Werte
Mache das Budget negativ
Belasse das IST postiv
dann zeigt die Summe die Differenz
Weg B: Berechnete Felder
Um berechnete Felder nutzen zu können, müssen Minuend und Subtrahend (https://www.matheretter.de/wiki/subtraktion ) eigene Spalten der zugrundeliegenden Prozedur sein.
Dann kann man ein berechnetes Feld definieren: Differenz = Sum(SpalteA) - Sum(SpalteB).
Man kann keine berechneten Felder erstellen, wenn eine Spalte verschiedene Ausprägungen hat.
2.4. Empfehlungen für gute Performance
2.4.1. Design der Abfrage
Jede Spalte weniger steigert die Performance.
Textspalten verbrauchen mehr Übertragungskapazität als numerische Spalten.
Je größer die Datenmenge wird, umso stärker spielt die “zip/unzip”-Zeit bei der Webkomprimierung eine Rolle.
2.4.2. Design der Pivot-Tabelle
Das Layout sollte zusammengeklappt gespeichert werden.
Generell sollte man im Layout nicht zu viele Zeilen erzeugen - max. 1000 zusammengeklappte Zeilen.
In einem Layout mit einer hoher Zeilenzahl, was max. 20 zusammengeklappten Zeilen entspricht, sollte man nicht zu viele Spalten erzeugen.
2.5. Einschränkungen
Ein Datenfeld kann nicht mehrfach als Fakt verwendet werden (nicht zugleich Summe und Anzahl zeigen) - außer es wird ein berechnetes Feld (siehe “Berechnete Felder” unter https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.2.1.Optionen-Pivot-Tabelle) für das Zweite genutzt (Berechnung = Wert * 1).
Felder können nicht auf Basis von Feldern berechnet werden, die Sonderzeichen / Umlaute enthalten.
Es ist keine feingranulare bedingte Formatierung (z.B. Werte größer als 100 = grün) möglich.
Es sind keine In-Cell-Diagramme (Sparklines) möglich.
Der Name des Factorytabs darf keine Sonderzeichen enthalten (z.B. "/" ).
2.6. Datenbankkopplung
Neue Spalten in der Prozedur sind in der Auswahlliste verfügbar und stören nicht die konfigurierte Oberfläche.
Gelöschte Spalten in der Prozedur verschwinden automatisch aus der Oberfläche.
3. Expertenbereich
Der Expertenbereich richtet sich an Benutzer mit fortgeschrittenem SQL-Wissen und Zugriff auf ein SQL Server Management Studio. Hier werden tiefergehende Hintergründe ausgeleuchtet.
3.1. Einrichtung des Tabs
Die Datenquelle ist eine gespeicherte Prozedur (Stored Procedure) oder ein SQL-Befehl, der beim Anlegen des Tabs direkt in einem Editor eingegeben wird (siehe: https://help.saxess-software.de/oct-handbuch/v511/3-3-8-2-pivot-tabelle#id-(v511)3.3.8.2.Pivot-Tabelle-3.3.8.2.1.Tab%E2%80%9CPivot-Tabelle%E2%80%9Dhinzuf%C3%BCgen).

Schema und Name der gespeicherten Prozedur sind beliebig.
Damit eine gespeicherte Prozedur dem Benutzer im Standard zur Auswahl angeboten wird, muss in den Metadaten die Eigenschaft “SX_UserHint” mit einem Text gefüllt sein.
Die gespeicherte Prozedur muss abhängig von der Ebene, auf der sie aufgerufen wird, die folgenden Parameter haben (Die Parameter müssen nicht zwingend von der Prozedur verarbeitet werden.):
Cluster - @Username, @ParamterJSON
Factory - @Username, @FactoryID, @ParameterJSON
Productline - @Username, @FactoryID, @ProductlineID, @ParameterJSON
Der Parameter @ParameterJSON ist ein Universalparameter - er ist dafür ausgelegt, beliebige Parameterwerte im JSON Format an die Prozedur zu übertragen.
Die gespeicherte Prozedur muss genau ein Resultset zurückgeben, nicht mehrere - immer SET NOCOUNT ON am Anfang der gespeicherten Prozedur setzen.
Die Prozedur sollte eine Sicherheitsprüfung machen, durch Ermittlung des TransactUsernames und JOIN mit system.trUserRights.
Die Prozedur sollte einen API-Logeintrag schreiben.
Filter werden im Layout als EXCLUDE gespeichert - neue Elemente sind also automatisch enthalten.
Beispiel: Ein Landesfilter existiert mit den Werten "Deutschland" und "Spanien". Man filtert auf "Deutschland" und speichert die Konfiguration. Was passiert dann, wenn Frankreich in der Datenquelle auftaucht? In der Pivot-Tabelle sind dann Deutschland und Frankreich zu sehen, da die Konfiguration "nicht Spanien" gespeichert hat und alles andere zeigt. Das kann besonders dann zu unerwarteten Filtern führen, wenn man eine gefilterte Pivot aus einer MasterFactory ausrollt und die anderen Factorys in ihren Daten andere Werte im Filterfeld haben.

3.2. Fehlererkennung (mit DB-Zugriff)
3.2.1. FAQ
Falls der Tab nicht in der Liste der vorgeschlagenen Prozeduren erscheint:
Wurde in den Metadaten die Eigenschaft SX_UserHint belegt?
Liefert die Prozedur wirklich Daten für den aktuellen Benutzer?
z.B. testen durch die Ausgabe eines statischen Ergebnisses ohne Rechteprüfung.
Probleme mit der Spaltenbenennung in der Prozedur?
Die Prozedur darf nicht zwei Spalten mit gleichem Namen haben.
Die Spaltennamen dürfen keine Sonderzeichen enthalten.
Die Spalten dürfen keinen reservierten Namen haben - z.B. "Right" oder "Left".
Die Prozedur lässt sich für den OCTService nicht ausführen?
Als OCTService im Managementstudio anmelden und testen.
3.2.2. Andere Probleme
Fakten erscheinen nicht in der Liste für die Zahlenformatierung:
In der Datenbank mit CONVERT statt CAST die Konvertierung zu einer Zahl durchführen.
Die Parameter FactoryID / ProductlineID wurden nicht als optional deklariert.
3.3. Hinweise zur Performance
Die Perfomanceaussagen sind immer ohne die Zeit für die Datenbankabfrage getroffen. Die Laufzeit der Datenbankprozedur kommt hinzu, liegt aber nicht in der Performanceverantwortung der Applikation. Lokale Performancetests erfolgten auf virtuellen Maschinen mit 8 GB RAM, 4x CPU (Xeon E3 v6 1505 3.0 GHz), NVMe SSD Platten.
Kriterium | Im lokalen Netzwerk | In Cloud | Bemerkungen |
|---|---|---|---|
Anzahl der performant verwendbaren Zeilenzahl der Prozedurrückgabe | 200k - 500k (max 1.0 Mio) bei < 10 Spalten 100k - 200k bei 25 Spalten | ||
Ladezeit bei o.g. Zeilenzahl | 5 - 20 Sekunden | ||
Performancebeeinträchtigung durch Gruppierungen | gering | ||
Performancebeeinträchtigung durch Layoutspeicherung in expandierter Ansicht | hoch | ||
Perfomancebeeinträchtigung durch große Spaltenzahl der Prozedur | hoch |
3.3.1. Analyseschritte bei Performanceproblemen
Lieber mehrere kleine Prozeduren in der Datenbank (pro Pivot eine), statt einer großen Prozedur in der Datenbank - deren Daten im Frontend gefiltert werden pro Tab.
Laufzeit der Prozedur im SQL Server Management Studio (SSMS) testen (sollte < 10 Sekunden sein).
Laufzeit der Prozedur in den Entwicklerwerkzeugen des Browsers anschauen (sollte max. 2-3x der der DB sein sein).
Die Brutto-Datenmenge (unkomprimiert) sollte unter 250 MB liegen.
3.4. Testprozedur
Diese Prozedur kann in jeder Datenbank ausgeführt werden und als Quelle "result.spSamplePivot" für ein Pivot-Tab genutzt werden - sie braucht keine Tabelle, da sie ihre Daten selbst erzeugt.
Es kann in der Testprozedur folgendes konfiguriert werden:
die Anzahl der zu erzeugenden Zeilen.
ob diese ihre Daten materialisieren soll.
/*
Author: Gerd Tautenhahn
Created: 2020/06
Summary: Sampledata for Pivottables
For 500k records with @Static = 1
- first execution needs 15 sek
- second execution needs around 6 sec
For 200k records with @Static = 1
- first execution needs 6 sek
- second execution needs 2 sec
Testcall
EXEC result.spSamplePivot 'SQL',''
*/
DROP PROCEDURE IF EXISTS result.spSamplePivot;
GO
CREATE PROCEDURE result.spSamplePivot (
@Username NVARCHAR(255),
@FactoryID NVARCHAR(255) = '',
@ProductLineID NVARCHAR(255) = '',
@ParameterJSON NVARCHAR(MAX) = ''
)
AS
BEGIN
SET NOCOUNT ON
DECLARE @Counter INT = 200000; -- set number of records to create here
DECLARE @Static INT = 1;
DECLARE @CreatedRows INT = 1;
-- if a static table already exists, deliver its content else create content
IF @Static = 1 AND OBJECT_ID (N'tPivotsample', N'U') IS NOT NULL
BEGIN
SELECT * FROM dbo.tPivotsample
END
IF @Static = 0 OR OBJECT_ID (N'tPivotsample', N'U') IS NULL
BEGIN
DROP TABLE IF EXISTS #tmp;
CREATE TABLE #tmp
(
RowNumber INTEGER NULL
,CompanyID INTEGER NULL
,CostCenterID INTEGER NULL
,AccountID INTEGER NULL
,CompanyName NVARCHAR(255) COLLATE DATABASE_DEFAULT NULL
,CostCenterName NVARCHAR(255) COLLATE DATABASE_DEFAULT NULL
,AccountName NVARCHAR(255) COLLATE DATABASE_DEFAULT NULL
,BookingText NVARCHAR(4000) COLLATE DATABASE_DEFAULT NULL
,BookingMonth INTEGER NULL
,BookingDate DATE NULL
,ValueDebit MONEY NULL
,ValueCredit MONEY NULL
,ValueBalance MONEY NULL
);
WHILE @Counter + 1 > @CreatedRows
BEGIN
INSERT INTO #tmp
SELECT
@CreatedRows AS RowNumber
,@CreatedRows/10000 +1 AS CompanyID
,@CreatedRows/1000 +1 AS CostCenterID
,@CreatedRows/10 + 1 AS AccountID
,'Company ' + CAST(@CreatedRows/10000 + 1 AS NVARCHAR(255)) AS CompanyName
,'CostCenter ' + CAST(@CreatedRows/1000 + 1 AS NVARCHAR(255)) AS CostCenterName
,'Account ' + CAST(@CreatedRows/10 + 1 AS NVARCHAR(255)) AS AccountName
,'Booking text about this booking item.' AS BookingText
,CAST (RAND ()*12+1 AS INTEGER) AS BookingMonth
,DATEFROMPARTS(2020,CAST (RAND ()*12+1 AS INTEGER),15) AS BookingDate
,RAND () * 100 AS ValueDebit
,RAND () * 100 AS ValueCredit
,RAND () * 1000 AS ValueBalance
SET @CreatedRows = @CreatedRows +1;
END
SELECT * FROM #tmp;
IF @Static = 1
BEGIN
SELECT * INTO tPivotSample FROM #tmp;
END
IF @Static = 0
BEGIN
DROP TABLE IF EXISTS dbo.tPivotsample;
END
END
RETURN 200;
END
GO
-- no GRANT, Factoryservice is already owner of the result schema
3.5. Technischer Hintergrund
Die der Pivot-Tabelle zugrunde liegende Komponente ist hier näher beschrieben. https://js.devexpress.com/Demos/WidgetsGallery/Demo/PivotGrid/FieldPanel/Angular/Light/
Nicht alle dort beschriebenen Funktionen sind in OCT implementiert - sollten Sie welche davon wünschen, sprechen Sie uns an.