3.2. Regulierung der Datenbankgröße
Dieser Artikel behandelt den Umgang mit zu groß gewordenen OCT Datenbanken und wie man deren Entstehung vermeidet. Der Artikel ist für SQL Server “on-premises” geschrieben - viele Teile gelten aber auch für SQL Server PaaS auf Azure.
Version: Dieser Artikel ist mindestens gültig ab der Version 5.7.
1. Voraussetzungen
Um die Anleitungen aus diesem Artikel nachzuvollziehen benötigen Sie:
Zugriff auf den Datenbankserver per SQL Server Managementstudio mit der Rolle: “sysadmin”.
Zugriff auf die Festplatte des SQL Servers, um Dateigrößen einzusehen.
2. Problembeschreibung
2.1. Gründe für eine zu große OCT Datenbank
Das Wiederherstellungsmodell steht nicht auf “Einfach”.
Es werden sehr umfangreiche Logs geschrieben (sehr vielen Zeilen, oder sehr große Logtexte in NVARCHAR(MAX) Spalten).
Transaktionen erzeugen sehr große temporäre Datenbestände.
Es gibt sehr viele DELETE / INSERT Operationen über viele Zeilen (bei Datenintegration immer der Fall).
Es gibt sehr viele SHRINK Nebenwirkungen.
Führen Sie wenn möglich nicht (regelmäßig/häufig) ein SHRINK der Datenbank durch - diese wird dadurch immer stärker fragmentiert und langsamer.
Verstehen Sie den tatsächlichen Grund des Größenwachstums und beheben Sie das Problem.
2.2. Wo sieht man die Größe der Datenbank?
Auf der Festplatte des Computers…
…liegt eine oder mehrere Datendatei(en) (mdf) und eine oder mehrere Logdatei(en) (log).
Deren genaue Verortung wird bei der Anlage der Datenbank bestimmt.
Man sieht die Speicherorte im SQL Server Management Studio in den Eigenschaften der Datenbank:
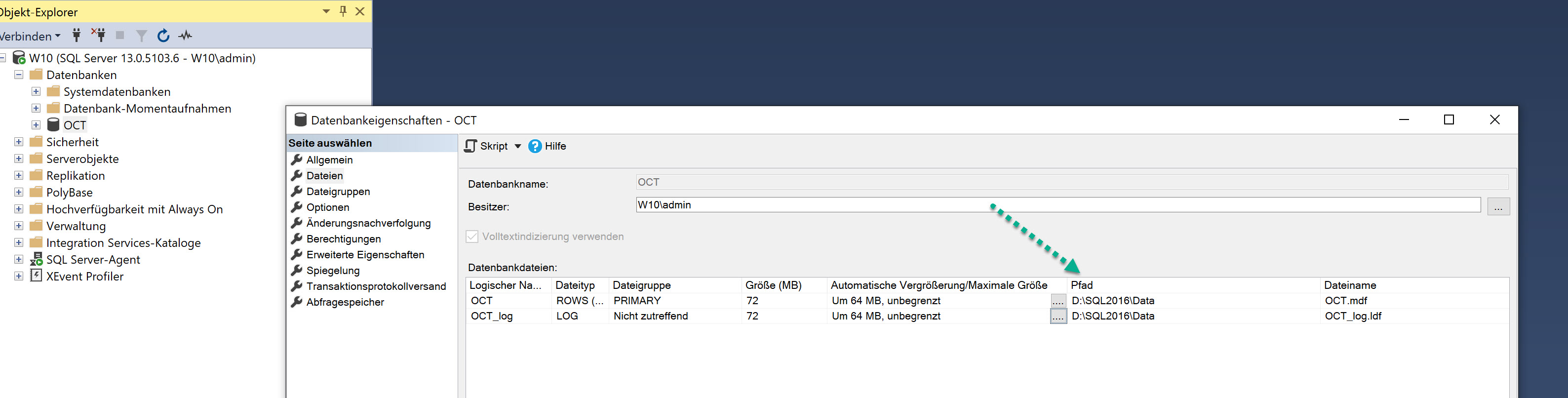
In der Datenbank…
…sieht man unter den Datenbankeigenschaften die Gesamtgröße (Datenbank plus Log).
Unter verfügbarer Speicherplatz sieht man, wieviel davon “Luft” ist - zur Zeit also nicht von der Datenbank gebraucht wird.
Der verfügbare Speicherplatz ergibt sich dadurch, dass die Datenbankdateien vorsorglich um eine bestimmte Größe vergrößert werden (siehe Screenshot oben, immer um 64MB)
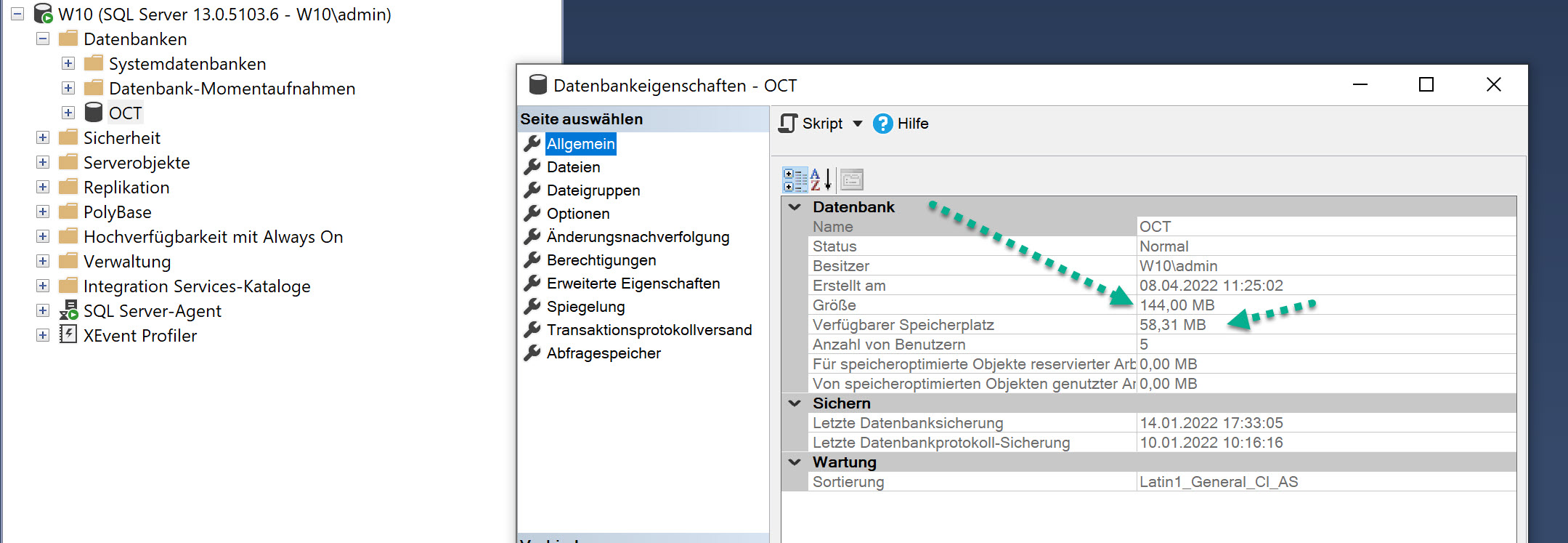
In den Details des Objektexplorers (F7) sieht man den Speicherbedarf pro Tabelle und kann danach sortieren, wenn man sich diese Spalten mit einblenden lässt:
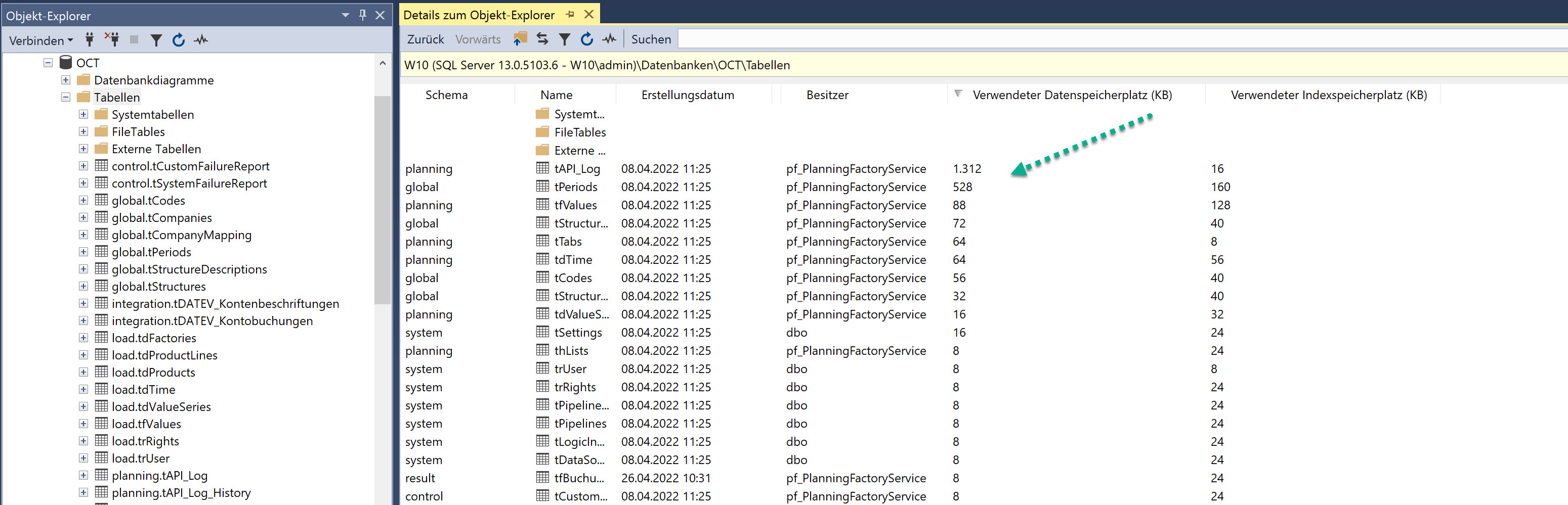
Zusammengefasst sollten Sie zunächst erstmal folgendes feststellen:
Ist das Problem die Datendatei (mdf) oder die Logdatei (ldf)?
Falls es die Datendatei ist - welche Tabellen sind die großen Brocken und damit die Ursache des Problems?
3. Diagnose und Lösung
3.1. Wiederherstellungsmodell der Datenbank
Das Wiederherstellungsmodell der Datenbank beeinflusst die Größe der Logdateien:
Im Wiederherstellungsmodell “Vollständig” merkt sich die Datenbank alle Änderungen an sämtlichen Datensätzen, wodurch das Log schnell sehr groß wird. Der große Vorteile des Modells ist, dass man per Point-in-Time Restore die Datenbank auf jeden beliebigen Zeitpunkt zurücksetzen kann.
Im Wiederherstellungsmodell “Einfach” wird das Datenbanklog nach jeder abgeschlossenen Transaktion geleert - es wird nur so groß wie es die größte Transaktion temporär erfordert.
In OCT Datenbanken werden regelmäßig sehr große Datenmengen bewegt. Entweder durch Datenintegrationsprozesse, oder durch sehr umfangreiche Kalkulationsprozesse, welche z.B. “result”-Daten erzeugen. Im Modell “Vollständig” würden daher extrem große Datenmengen geloggt, die nicht wertvoll für eine Wiederherstellung sind.
OCT Datenbanken müssen daher immer im Wiederherstellungsmodell “Einfach” laufen!
Sollten Sie aus bestimmten Gründen das Wiederherstellungsmodell “Vollständig” wählen wollen, beschäftigen Sie sich unbedingt intensiv mit dem Thema Backup und Transaktionsprotokollsicherung - diese beeinflussen die Größe der Logdateien.
3.2. Umfang der Logdaten
Logdaten innerhalb der Datenbank entstehen in den Tabellen:
planning.tAPI_Log
system.tProcessLogs
system.tPipelineLog
system.tPipelineStepLog
Sie können grundsätzlich die Inhalte der Logtabellen mittels “TRUNCATE Table” löschen, ohne die Datenbestände von OCT zu gefährden. Allerdings geht dadurch die Anzeige der Ausführungshistorie verloren.
Die Daten im Log können sehr groß werden durch:
viele geloggte Zeilen.
sehr große geloggte Inhalte.
Wenn eine der folgenden Tabellen zu groß wird, kann das die beschriebenen Ursachen haben:
planning.tAPI_Log
sehr häufige “Powerload”-Prozesse
umfangreiche Lade- / Kalkulationsprozesse
umfangreiche Rebuilds im “DataEntry”-Bereich
sehr große Products mit sehr langen Formeln / Texten
system.tProcessLogs
umfangreiche ETL-Logausgaben
system.tPipelineLog
viele Prozessausführungen (z.B. minütlich)
system.tPipelineStepLog
umfangreiche ETL-Logausgaben
laufende Logausgabe nutzt Methode APPEND statt REPLACE
3.3. Große temporäre Datenbestände
In der hier betrachteten Ausgangssituation sind die Datendateien klein - mit nächtlich wiederkehrenden & großen Logdateien.
Dabei entstehen in einem Prozess (meist bei der nächtlichen Datenintegration) große temporäre Daten, welche anschließend nicht mehr gebraucht werden.
Ursachen für diese Ausgangssituation können die folgenden sein:
Sie schreiben einen komplexen/großen JOIN mit vielen SUBSELECTS und “WITH”-Statements - ganz am Ende wird auf Mandant, Kostenstelle, etc… gefiltert.
Der SQL Server wird dafür ggf. einen Ausführungsplan wählen müssen, bei dem er vor einer möglichen Filterung zunächst alle Daten holen (ggf. noch sortieren) und joinen muss. Der SQL Server schreibt immer alle Daten zuerst ins Log, dann in eine Datendatei. Dadurch erzeugt der SQL Server temporär eine sehr große Logdatei.
Mögliche Lösungsansätze:
Einfache Statements schreiben. Mehrere einfache Statements liefern eine bessere Performance als ein großer & komplexer JOIN.
So früh wie möglich im Prozess filtern.
Statt “WITH”-Statements bevorzugt temporäre Tabellen nutzen.
Ausführungspläne vom SQL Server lesen zu lernen.
3.4. Multiple DELETEs/INSERTs und falsches Shrink
In der hier beschriebenen Ausgangssituation braucht die Tabelle viel Speicherplatz, obwohl sie (berechnet) nicht viel Speicherplatz brauchen dürfte. Diese Tabelle ist möglicherweise durch viele DELETEs / INSERTs, tägliche SHRINKs, etc… so fragmentiert worden, dass sie auf zu viele Seiten verteilt ist.
Möglicher Lösungsansatz:
ALTER TABLE [Tabellenname] REBUILD
Falls die Tabelle danach deutlich kleiner ist, dann war es genau dieses Problem.
Hier im Beispiel reduziert sich eine Tabelle durch den Rebuild von 56.094 MB auf 57 MB. Das entspricht weniger als 1% der Ausgangsgröße:
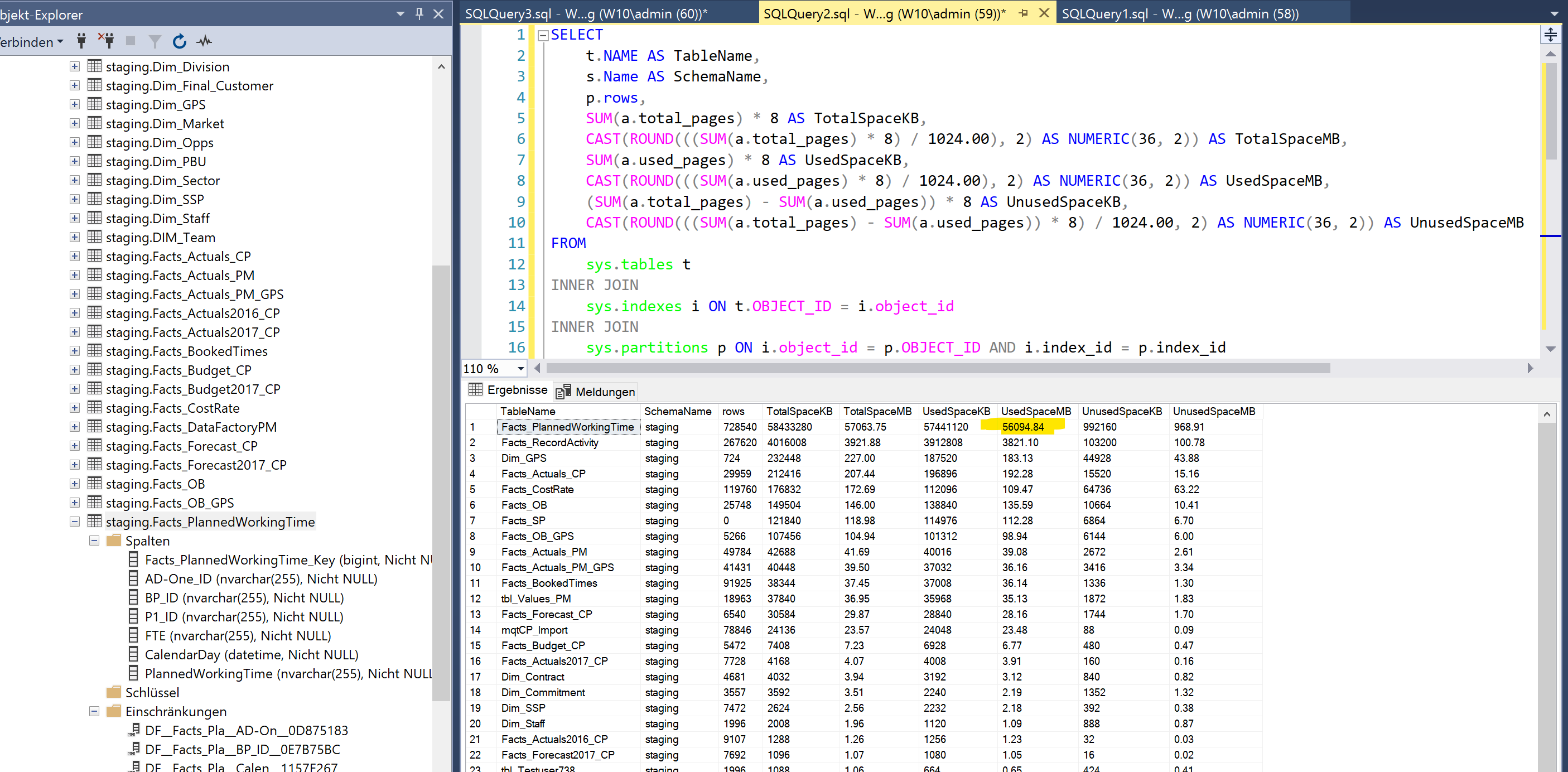
Vor “ALTER TABLE ..REBUILD”
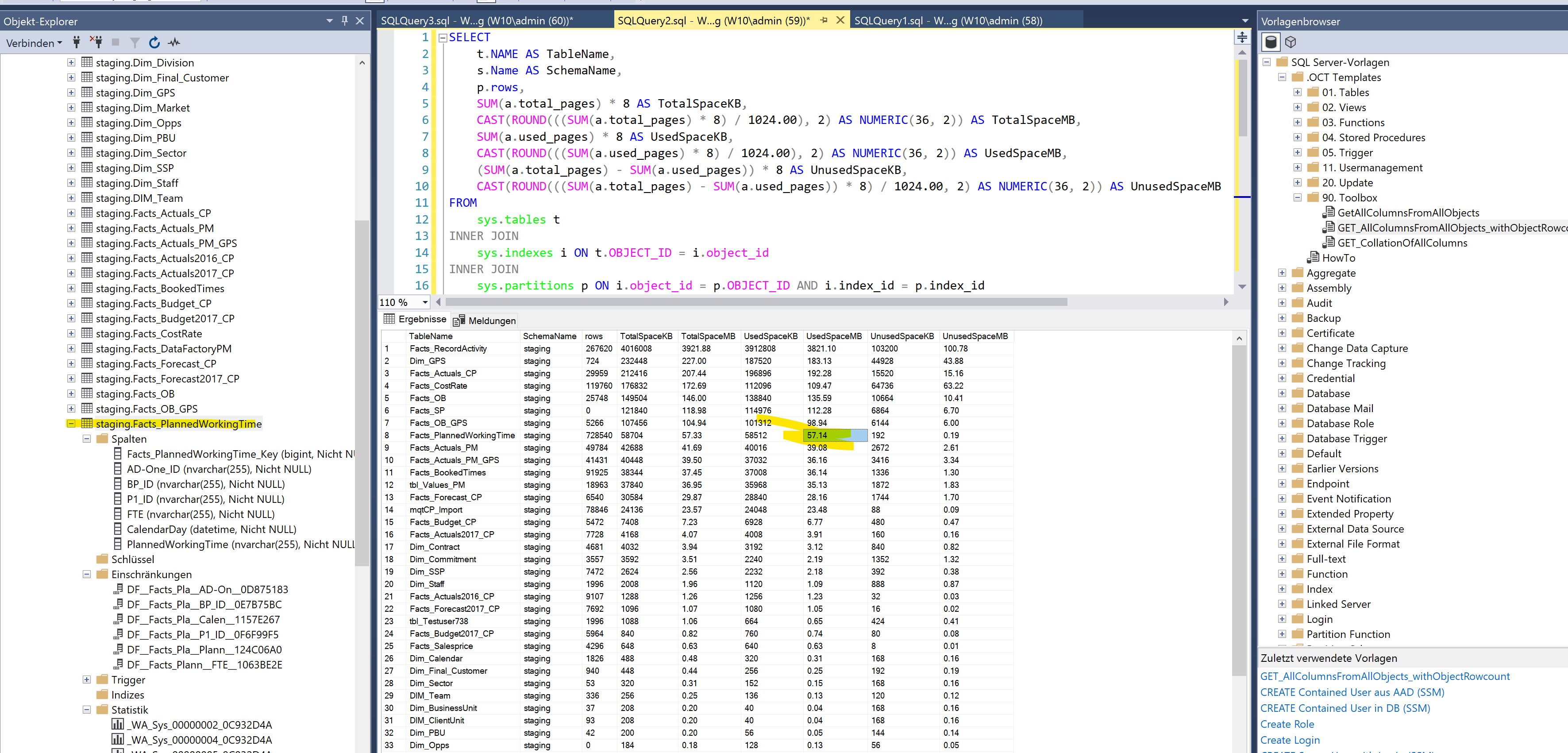
Nach “ALTER TABLE .. REBUILD”
4. Expertenbereich
Hier folgen in der Zukunft noch detaillierte Inhalte zu den Schwerpunkten:
4.1. Wie groß sollte meine Datenbank überhaupt sein?
Anleitung für die Berechnung der Datenbankgröße
4.2. Größe der “tempdb”?
Die TempDB besteht aus vielen Datendateien (abhängig von Prozessoranzahl) und kann durch intensive Nutzung von “temp”-Tabellen groß werden.
Ursache sind häufig schlecht formulierter JOINs oder Stored Procedures.
##Tabellen (global temporär) werden nur beim Neustart des SQL Servers gelöscht.